
Projekt FAIR Data Spaces: Verteiltes Datensystem für Industrie und Forschung
Mit dem Projekt FAIR Data Spaces entsteht ein gemeinsamer Datenraum von Gaia-X und der NFDI, in dem Nutzende auf die Daten in einer sicheren, transparenten und einheitlichen Weise zugreifen können. Gleichzeitig behalten die Datenbesitzenden die Kontrolle über den Zugang zu ihren Daten. Welche Rolle dabei die FAIR-Prinzipien spielen und warum Gaia, eine aus dem Chaos entstandene griechische Gottheit als Namensgeberin passend gewählt wurde, berichtet Katja Kornetzky im Interview.
im Interview mit Katja Kornetzky (Nationale Forschungsdateninfrastruktur – NFDI)

FAIR Data Spaces ist ein Projekt zur Schaffung eines gemeinsamen, Cloud-basierten und FAIRen Datenraums für Industrie und Forschung. Katja Kornetzky, im Projekt FAIR Data Spaces für Roadmapping und Community-Building zuständig, gibt einen Einblick in das Projekt:
Was ist das Ziel eures Projekts?
Im Projekt FAIR Data Spaces haben wir organisatorische und technische Bausteine für einen gemeinsamen, Cloud-basierten Datenraum für Industrie und Forschung geschaffen. Insbesondere haben wir an der Schnittstelle zwischen Industrie und Forschung auf die Anwendung der FAIR-Prinzipien geachtet. Deshalb heißt das Projekt FAIR Data Spaces.
Ein Datenraum (PDF) ist ein verteiltes Datensystem, das auf gemeinsamen Richtlinien und Regeln basiert. Die Nutzenden können dort auf die Daten in einer sicheren, transparenten und einheitlichen Weise zugreifen. Die Datenbesitzenden haben die Kontrolle darüber, wer Zugang zu ihren Daten hat und zu welchem Zweck und unter welchen Bedingungen sie genutzt werden können. Solche Datenräume ermöglichen digitale Souveränität, weil die Daten immer im Besitz des Unternehmens, einer Einrichtung oder eines Forschungsinstituts verbleiben.
Was ist das Besondere an den FAIR Data Spaces?
In unserem Projekt wurden die föderierte, sichere Dateninfrastruktur Gaia-X (aus der Industrie) und die Nationale Forschungsdateninfrastruktur (NFDI) (aus der Forschung) zu einem gemeinsamen Datenraum unter Einhaltung der FAIR-Prinzipien verbunden. Eine Besonderheit ist zudem, dass Gaia-X ein Projekt auf europäischer Ebene ist, während die NFDI ein nationales Vorhaben ist und vor allem die Forschenden in Deutschland unterstützt. Eine grenzübergreifende Zusammenarbeit!
Was habt ihr in eurem Projekt schon erreicht?
Das war sehr spannend: 2021, als es losging, gab es nämlich noch keine konkreten Empfehlungen von Gaia-X. Die entwickelten sich erst nach und nach, zum Beispiel mit dem White Paper von Gaia-X (PDF) 2022. Ende 2023 waren dann einige Spezifikationen verabschiedet, es gab eine erste Version der sogenannten Federation Services. Diese beinhalten Authentifizierungsdienste, Wallets für digitale Nachweise und Katalogdienste.
Wir sehen: Nicht umsonst ist Gaia eine aus dem Chaos entstandene griechische Gottheit!
Parallel dazu begannen schon die Konsortien der NFDI:
Beispielsweise erstellte NFDI4Biodiversity, ein Konsortium der Biowissenschaften, gemeinsam mit einem Startup namens Geo Engine einen Atlas der Libellen und erarbeitete noch weitere Use Cases. Die Entwickelnden orientierten sich kontinuierlich an den Empfehlungen der Gaia-X Federation Services, und so kam es, dass FAIR Data Spaces sogar ein Gaia-X qualifiziertes Projekt wurde.
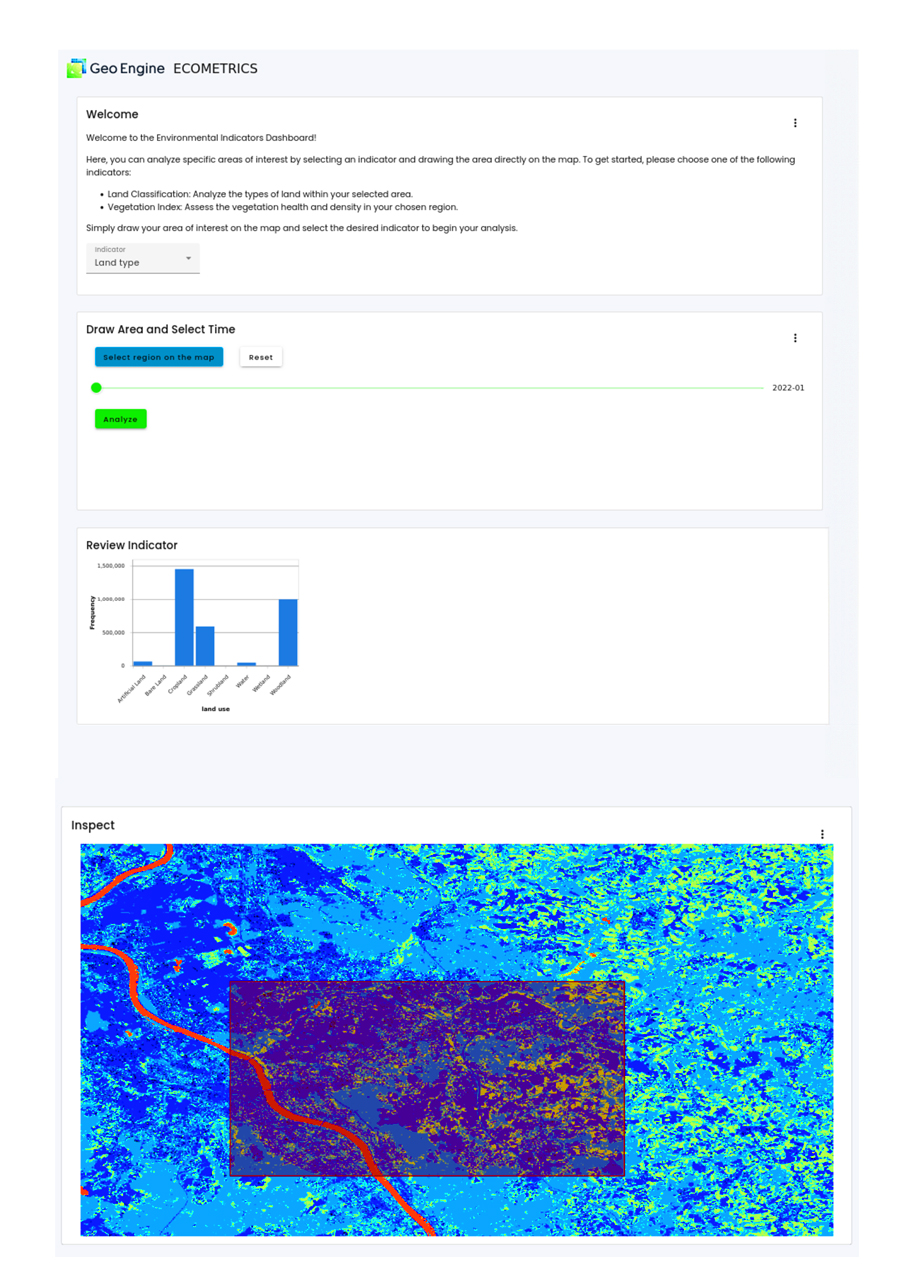
Geo Engine: Mit der Funktion ECOMETRICS des Geo-Engine-Dashboards können ökologische Indikatoren wie Vegetation oder Landnutzung visualisiert und analysiert werden
Im Bereich Gesundheit, bei NFDI4Health, sorgt das Unterprojekt PADME/ PHT für bessere verteilte Analysen von Gesundheitsdaten. In diesem Fall werden die Algorithmen zu den Daten gebracht und stellen so sicher, dass sensible Gesundheitsdaten ihre Quelle nie verlassen und die Besitzer:innen der Daten die Kontrolle behalten. Dieser Paradigmenwechsel hilft bei der Einhaltung von Datenschutzgesetzen sehr.
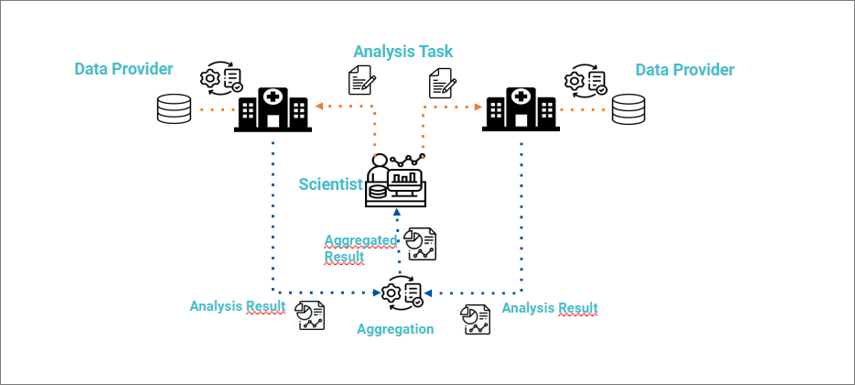
Personal Health Train(PHT) von NFDI4Health: Das PHT-Konzept: Algorithmen zu den Daten bringen durch verteilte Analysen (distributed analytics)
Als weiteres Beispiel finde ich die Kooperation mit NFDI4Ing erwähnenswert. Hier haben wir in FAIR Data Spaces einen Demonstrator zur Datenvalidierung entwickelt.
Welche Rolle spielt euer Projekt im Kontext von Open Science?
Open Science umfasst ja Strategien und Verfahren, um weitestgehend alle Bestandteile des wissenschaftlichen Prozesses transparent, nachvollziehbar und nachnutzbar zu machen. Damit eröffnen sich für die Wissenschaft und andere Akteur:innen neue Möglichkeiten im Umgang mit wissenschaftlichen Ressourcen und Erkenntnissen. Ich finde, allein dadurch, dass wir uns an die FAIRen Prinzipien halten, gewährleisten wir, dass wissenschaftliche Daten unter geregelten Bedingungen verfügbar sind. Zusätzlich halten sich auch die Industriepartner vermehrt an die FAIRen Prinzipien. Und das ist eine echte Bereicherung! In FAIR Data Spaces bekennen sich alle Beteiligten zu den Regeln. Dadurch fördern wir letztlich Open Science.
An wen richtet ihr euch mit eurem Projekt? Was haben zum Beispiel Forschende von eurem Projekt?
Alle Forschenden und auch Mitarbeitende der Industrie können von FAIR Data Spaces profitieren, weil mit FAIR Data Spaces ein organisatorischer und technischer Rahmen für den Austausch gegeben ist. Da unser Code als Open Source verfügbar ist, kann unser Datenraum auch selbst nachgebaut werden oder andere Projekte hängen sich bei NFDI4Biodiversity, NFDI4Health oder sogar NFD4Ing mit dran!
Welche Rolle spielen Bibliotheken in eurem Projekt?
Bibliotheken spielen eine wichtige Rolle. Die Mitarbeitenden verfügen über Kernkompetenzen in der Infrastrukturentwicklung und haben gute Verbindungen in die wissenschaftliche Community. Von beidem hat unser FAIR-Data-Spaces-Projekt sehr profitiert. Die ZBW hat als weltweit größte wirtschaftswissenschaftliche Fachbibliothek ihre Expertise beispielweise erfolgreich im Roadmapping und im Community-Building eingebracht. Im Mittelpunkt stand zu Beginn die konkrete Identifizierung der Ziele. Abschließend galt es, eine Community in Deutschland und Europa aufzubauen und diese weiter zu internationalisieren – mit Themen für Wissenschaft und Wirtschaft.
Die Technische Informationsbibliothek (TIB) wiederum hat im Bereich Interoperabilität einen wichtigen Beitrag geleistet. In unseren Datenräumen stellt Interoperabilität eine große Herausforderung dar, weil Daten aus unterschiedlichen Kontexten geteilt werden. Das TIB-Team hat die unterschiedlichen Ontologien aus Anwendungsbereichen untersucht und einen Mapping-Service erstellt. Der Schwerpunkt dieser Sammlung liegt auf der Gewährleistung der Interoperabilität und Wiederverwendbarkeit in Gaia-X, insbesondere für Organisationen.
Was können Bibliotheken von eurem Projekt lernen?
Mitmachen! Einmal mit konkreten Use Cases oder durch Mitarbeit bei Ontologien und Terminologien für bestimmte Fachbereiche.
Was würdet ihr anderen Projekten empfehlen?
Reden, reden, reden! …also sich vernetzen und austauschen, um Doppelarbeiten zu vermeiden und um sichtbar zu machen, was schon alles da ist.
Was war euer überraschendstes Learning?
Mich hat die Resonanz positiv überrascht. Es haben sich viele externe Partner:innen unserem Datenraum angeschlossen und wir konnten Kontakte zu zahlreichen interessanten Projekten knüpfen. Sphin-X ist beispielsweise ein Datenökosystem im Bereich Gesundheit, an dem sich alle großen Player in Deutschland beteiligen. Hier ist es auch auf jeden Fall sinnvoll, unsere Kompetenzen weiterhin einzubringen und mitzugestalten.
Das könnte Sie auch interessieren:
- NFDI Podcasts
- Open Economics Guide: Warum FAIR Data wichtig ist
- Data Stewards: zentrale Anlaufstelle für Forschungsdaten und Open Data
- Jubiläum re3data: 10 Jahre aktiv für die Öffnung von Forschungsdaten und eine Kultur des Teilens
- Horror Forschungsdatenmanagement: 4-Best-Practice-Beispiele für gelungene Gamifications
Wir sprachen mit:
Katja Kornetzky war ursprünglich Biologin, hat zwei Jahre mit einem DAAD-Stipendium in Japan gelebt und sich schon früh für Elektronik und Digitalisierung interessiert. In der Industrie war sie 20 Jahre lang Produktmanagerin für Software und Analysegeräte, am Fraunhofer-Institut für Optronik, Systemtechnik und Bildauswertung (IOSB) war sie Consultant für EU-Projekte und an der Uni Karlsruhe in mehreren Projekten für IoT und FAIRe Daten beteiligt. Jetzt ist sie im Direktorat der Nationalen Forschungsdateninfrastruktur (NFDI) angestellt und im Projekt FAIR Data Spaces für Roadmapping und Community-Building zuständig. Dabei informiert sie die Öffentlichkeit über neueste Ergebnisse und Netzwerke mit Akteur:innen aus verschiedensten Bereichen. Eine spannende Aufgabe!
Porträt: Katja Kornetzky©


Auf dem Weg zum nächsten Level: Interview zu Open Science in Finnland

Interview: Open Access-Preprints werden häufiger zitiert und geteilt

Kick-start für die deutsche GO-FAIR-Community: Zweiter Workshop offenbart Synergiepotenziale
View Comments

Barcamp Open Science 2024: Open Science und gefährdete Forschende
Was sind die wichtigsten Themen, Ressourcen sowie aktuellen Initiativen zur...