
ChatGPT & Co.: Wenn der Suchschlitz zur KI-Chatbox wird
Generative Sprachmodelle und KI-gestützte Recherchen legen gerade einen rasanten Siegeszug hin. Immer mehr Suchmaschinen setzen etwa auf Roboterchats, um die Suche durch das unmittelbare Finden zu ersetzen. Doch welche Implikationen sind damit verbunden – und was kommt da auf die wissenschaftlichen Bibliotheken zu?
von André Vatter
Die Behauptung, dass KI-Sprachmodelle gekommen sind, um zu bleiben, dürfte mittlerweile unwiderlegbar sein. Obwohl erst im November 2022 der Öffentlichkeit vorgestellt, hat ChatGPT in der kurzen Zeit einen rasanten Siegeszug hingelegt. Wie rasant dieser wirklich ausfiel, lässt sich am besten im Vergleich betrachten: Nach ihrer Gründung hatten Twitter zwei Jahre und Facebook immerhin noch zehn Monate gebraucht, um eine Basis von einer Million Nutzerinnen und Nutzer aufzubauen. ChatGPT schaffte dies in nur fünf Tagen. Zwei Monate nach dem Start gaben fast vierzig Prozent der Deutschen an, den Sprachroboter zu kennen oder ihn bereits ausprobiert zu haben.
Ein brutales Wettrennen
Doch so beeindruckend die private Adoptionsrate heute ist, so spannender sind doch Kapriolen, die ChatGPT die Unternehmenswelt schlagen lässt. Microsofts Ankündigung, das generative Sprachmodell in die eigene Suchmaschine Bing integrieren zu wollen, sorgte für blanke Panik beim unangefochtenen globalen Branchenführer Google. Dieser tüftelt zwar schon seit einiger Zeit an einer KI-gestützten Websuche, eine wirkliche Marktreife konnte aber bis heute noch nicht demonstriert werden. Es gibt einen Namen, “Bard“, doch über konkrete Integrationen hüllt sich CEO Sundar Pinchai in Schweigen. Dafür konnte wiederum Microsoft vor wenigen Tagen verkünden, dass die jahrzehntelang von Nutzerinnen und Nutzern kaum beachtete eigene Suchmaschine einen regelrechten Besucheransturm verkraften musste:
“We have crossed 100M Daily Active Users of Bing. This is a surprisingly notable figure, and yet we are fully aware we remain a small, low, single digit share player. That said, it feels good to be at the dance!”
In Redmond, Washington, befindet man sich in einem KI-Rausch. Künftig wird es bei Microsoft kaum noch einen Geschäftsbereich geben – ob B2B oder B2C –, in dem ChatGPT keine Rolle spielt.
Die Disruption geht auch an den kleinen Wettbewerbern nicht spurlos vorbei. Brave Search, die Netzsuchmaschine des US-amerikanischen Browserherstellers Brave Software Inc., hat kürzlich ein neues KI-Feature spendiert bekommen. Der “Summarizer” fasst nicht nur Sachverhalte am Kopf der Suchergebnisseite direkt zusammen, sondern gibt zu jedem gefundenen Ergebnis relevante Inhaltsangaben. Umwälzungen gibt es auch bei der datensparsamen Suchmaschine DuckDuckGo, die gerade “DuckAssist” gelauncht hat. Je nach Fragestellung klopft die KI Wikipedia auf relevante Informationen ab und bietet noch auf der Suchergebnisseite konkrete Antworten. Doch dies ist erst der Anfang: “This is the first in a series of generative AI-assisted features we hope to roll out in the coming months.”
Bei all diesen Integrationen von KI-Sprachmodellen in Suchmaschinen geht es nicht um eine Erweiterung des bestehenden, jeweiligen Geschäftsmodells. Es geht um eine vollständige Umwälzung in der Art, wie wir heute im Netz recherchieren, wie wir Ergebnisse interpretieren und sie verstehen.
Wie das Finden das Suchen ersetzt
Bestand nämlich das bisherige Angebot der Suche aus einem bemühten “Ich zeige dir, wo du vielleicht die Antwort finden kannst.”, so avanciert es in KI-Kombination plötzlich zu einem: “Hier ist die Antwort.” Seit ihrer Erfindung haben uns Suchmaschinen stets nur mögliche Wege aufgezeigt, wo sich Antworten auf unsere Fragen eventuell finden lassen. Tatsächlich war es auch nie das zwangsläufige Ziel werbebasierter Unternehmenskonzepte, Nutzerinnen und Nutzer eine schnelle Auskunft zu geben. Immerhin geht es darum, sie so lange wie möglich im eigenen Ökosystem zu halten, um die Wahrscheinlichkeit der Ad-Klicks zu maximieren. Das ist auch der Grund, weshalb Google irgendwann damit begann, allgemeinverfügbare Informationen – wie Uhrzeiten, Wetter, Börsenkurse, Sportergebnisse oder Fluginformationen – etwa in der sogenannten OneBox direkt auf den Suchergebnisseiten (SERPs) zu präsentieren. Hauptsache, niemand verlässt das Googleversum!
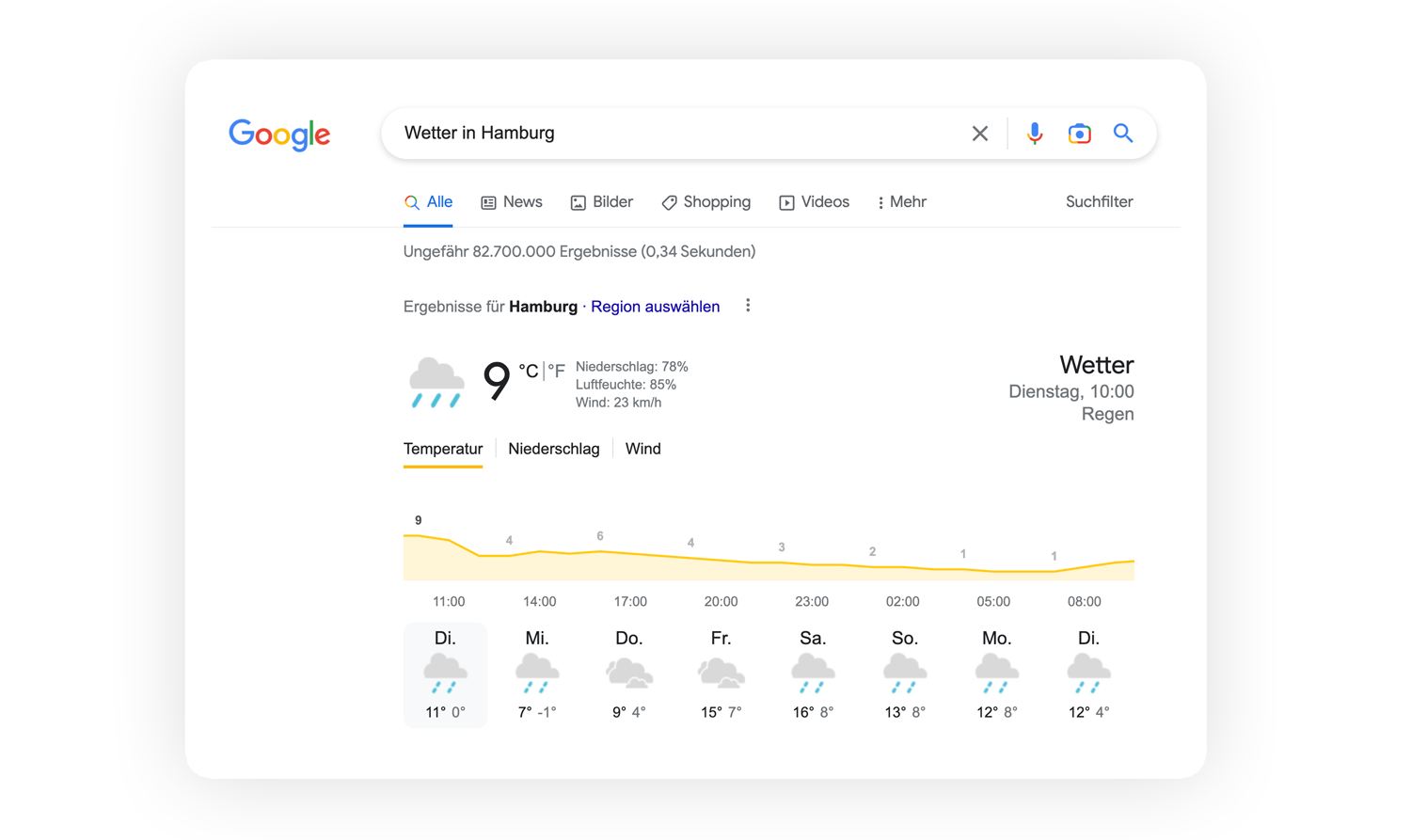
Intelligente Chatbots, wie ChatGPT, umgehen dieses Problem. Zum einen transformieren sie die Art der Suche, bei der Keywords durch Fragen ersetzt werden. Schon bald dürften sich viele Nutzerinnen und Nutzer von den so genannten “Suchbegriffen” oder gar Booleschen Operatoren verabschieden. Stattdessen lernen sie, ihre Prompts, ihre Kommunikation mit der Maschine, immer weiter zu tweaken und zu präzisieren. Und zum anderen lassen die Chatbots die Bedeutung der Originalquellen sinken; oft gibt es keine Veranlassung mehr, den Chat zu verlassen. Wer KI-gestützt sucht, will und bekommt eine Antwort vorgesetzt – und keinen Zettelkatalog mit Regalnummern.
Trotz aller Antworten bleiben Fragen offen
Man sieht jetzt schon: Der Komfort kommt nicht ohne kritische Implikationen daher. Etwa was die Transparenz der Quellen angeht, die wir unter Umständen nicht mehr zu Gesicht bekommen. Woher stammen sie? Wie wurde selektiert? Sind sie vertrauenswürdig? Kann ich gezielt auf sie zugreifen? Gerade im wissenschaftlichen Sektor sind belastbare Antworten auf diese Fragen unumgänglich. Andere Probleme kreisen um das Urheberrecht. Denn die KI erschafft ja keine neuen Informationen, sondern stützt sich etwa auf die Leistung von Journalistinnen und Journalisten, die im Netz publizieren. Wie werden sie vergütet, wenn niemand ihre Texte liest und man sich auf maschinelle Zusammenfassungen verlässt?
Datenschutzrechtliche Bedenken werden nicht lange auf sich warten lassen. In der Kommunikation mit der Maschine entsteht mit der Zeit eine enge Beziehung; je mehr sie von uns weiß und unsere Perspektive nachvollziehen kann, desto akkurater kann sie antworten. Außerdem müssen die Modelle trainiert werden. Personalisierung bedeutet allerdings im Gegenzug zwangsläufig ein kritischer Reichtum an Daten, der in Händen Dritter liegt. In den Händen von Unternehmen, die komplett neue Geschäftsmodelle um ein Frage-Antwort-Spiel bauen müssen – nicht wenige davon werden werbegestützt sein.
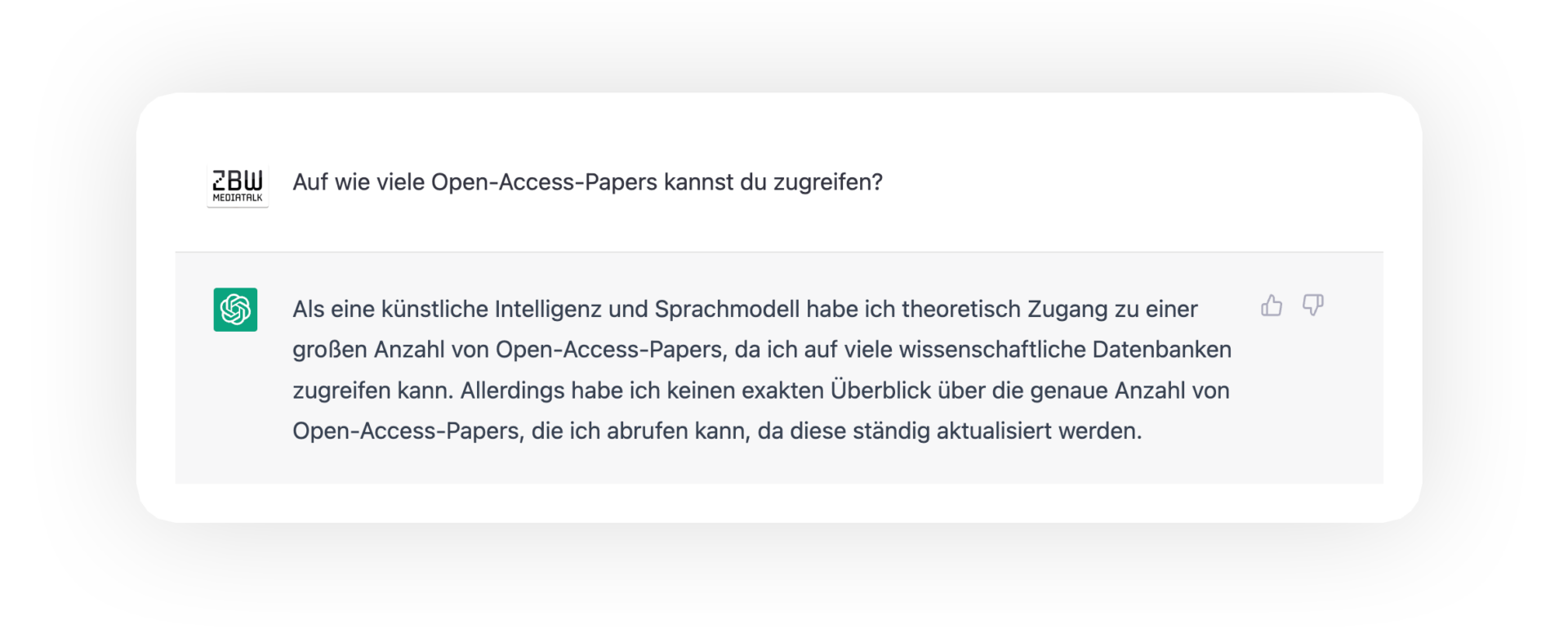
KI gibt Antworten. Aber derzeit nicht wirklich auf alle Fragen. Die Suche wird sich in kurzer Zeit radikal verändern. Auch wissenschaftliche Bibliotheken mit Angeboten im Netz werden sich entsprechend orientieren und anpassen müssen. Vielleicht wird der “Katalog” als statisches Verzeichnis oder Liste einen Schritt in den Hintergrund treten. Stellen wir uns nur kurz das Szenario einer KI vor, die Zugriff auf einen gigantischen Korpus von Open-Access-Texten hat. Forschende greifen simultan auf mehrere Quellen zu, lassen sie sortieren, inhaltlich zusammenfassen und einordnen: Wurden Thesen gestützt oder falsifiziert? Es ergibt sich das Bild einer neuen Mechanik, wie wissenschaftliche Erkenntnisse zugänglich und umfänglich erfassbar gemacht werden können. Vorausgesetzt natürlich, dass die zugrundeliegenden Inhalte offen zugänglich sind – auch aus dieser Perspektive ertönt hier erneut ein deutliches Plädoyer für eine offene Wissenschaft.
Also, wie implementieren wissenschaftliche Bibliotheken künftig diese Technologien? Wie schaffen sie Quellentransparenz, wie schaffen sie Vertrauen und welche Medienkompetenzen stehen im Vordergrund, wenn eine neue, maschinengerechte Kommunikation zum Werkzeugkasten der Recherche gehört? Viele Fragen, viele Unsicherheiten – aber zugleich auch ein großes Potenzial für die zukünftige Informationsversorgung. Ein Potenzial, das Bibliotheken nutzen sollten, um den unaufhaltbaren Wandel aktiv mitzugestalten.
Das könnte Sie auch interessieren:
- Hackathon Coding.Waterkant: Wie man Bibliotheksservices durch Chatsbots und künstliche Intelligenz besser machen kann
- Horizon Report 2022: Trends wie hybrides Lernen, Mikrozertifikate und künstliche Intelligenz verstärken sich
- KI in wissenschaftlichen Bibliotheken, Teil 1: Handlungsfelder, große Player und die Automatisierung der Erschließung
- KI in wissenschaftlichen Bibliotheken, Teil 2: Spannende Projekte, die Zukunft von Chatbots und Diskriminierung durch KI
- KI in wissenschaftlichen Bibliotheken, Teil 3: Voraussetzungen und Bedingungen für den erfolgreichen Einsatz


8 Thesen für die Arbeitswelt 4.0 – Hochschul-Bildungs-Report 2020

Studie zu Science 2.0: Zwischen Video, Wikipedia und Content-Sharing

Diskussionspapier: Neue Indikatoren für Open Science und Open Innovation
View Comments

Von eingebetteter KI bis NFT: Digitale Trends 2023 überbrücken neue Herausforderungen
von Birgit Fingerle Wie lassen sich die durch die Pandemie und technologische...