
Wikidata und Open Science: ein Modell für offene Datenarbeit
Wikidata ist eine sprachunabhängige Faktendatenbank und gehört zur Wikimedia-Familie, von der besonders Wikipedia bekannt ist. Timo Borst erläutert im Interview die Dimensionen und besondere Bedeutung dieser Datenbasis, insbesondere im Kontext von Open Science.
Ein Interview mit Dr. Timo Borst

Die freie Enzyklopädie Wikidata ist die größte kollaborativ erstellte Sammlung offener Daten weltweit. Die in Wikidata vorgehaltenen Daten sind untereinander verknüpft und für alle jederzeit frei nutzbar. Aktuell umfasst die Plattform über 90 Millionen Datenobjekte, es sind rund 25.000 Editor:innen aktiv. Damit ist Wikidata die am intensivsten genutzte Datenbasis innerhalb der Wikimedia-Gemeinschaft.
Logo Wikidata, lizensiert unter (CC BY-SA 3.0).
Grundidee von Wikidata ist es, eine sprachunabhängige Faktendatenbank zu schaffen, die enzyklopädisches Wissen in maschinenlesbarer Form bereithält – neben der Wikipedia auch für andere Anbieter:innen von Inhalten. Aber welche Rolle spielt Wikidata im Kontext von Open Science? Dazu haben wir mit Dr. Timo Borst gesprochen, der die ZBW-Abteilung „Innovative Informationssysteme und Publikationstechnologien“ leitet und sich in der ZBW um das Thema Softwareentwicklungen kümmert.
Wie siehst du die Bedeutung von Wikidata für die Forschung?
Insbesondere in der biomedizinischen Forschung, aber auch in den Geisteswissenschaften gibt es hierzu mittlerweile einige interessante Initiativen und auch Ergebnisse. Wikidata praktiziert seit jeher, den FAIR-Prinzipien entsprechend, die Auffindbarkeit, Zugänglichkeit, Interoperabilität und Wiederverwendbarkeit seiner Daten. Dabei ist diese Datenbasis weniger ein Abbild aktueller datenbasierter Forschung – Wikidata versteht sich laut eigener Policy ausdrücklich als „secondary database“ –, sondern vielmehr Materialisierung eines enzyklopädischen Wissens, wie es Grundlage auch datengetriebener Forschung ist.
Hinzu kommt, dass man über bestimmte Entitäten – Konzepte, Personen, Orte oder Ereignisse – mittels Wikidata-Identifiern beziehungsweise den darüber verlinkten jeweiligen Identifier-Systemen direkt über das Web beziehungsweise in entsprechenden Anwendungen kommunizieren kann. In diesem Sinne bietet Wikidata also das Modell für eine konsequent webbasierte Wissenschaftskommunikation.
Hast du selbst bei deinen Projekten oder Entwicklungen schon von Wikidata profitiert?
Ja, durchaus. In der ZBW machen wir ja im weitesten Sinne informationswissenschaftliche Forschung und Entwicklung, indem wir Metainformationen zu Fachinformationen erheben, auswerten und verarbeiten. In diesem Zusammenhang bietet Wikidata eine sehr umfangreiche Quelle für formale Metadaten, zum Beispiel im Kontext von Journals. So war ich unlängst selbst erstaunt, wie viele Zeitschriftentitel Wikidata beinhaltet und zu wie viel anderen Identifier-Systemen wie denen von ISSN, Scopus oder Open Citations jeweils Verknüpfungen bestehen. Da ist Wikidata vollständiger als jedes Verlagssystem oder manch andere bibliografischen Aggregatoren.
Dadurch, dass sich Wikidata nicht auf einen oder mehrere Inhaltsanbieter, ferner auf kein bestimmtes Projektkonsortium gründet, hat man da Verknüpfungen aus allen möglichen beitragenden Communities. Und dabei haben wir bisher nur die konsumptorische Seite betrachtet – Wikidata bietet natürlich auch hervorragende Möglichkeiten, vorzugsweise über Programme und maschinelle Schnittstellen mit eigenen offenen Daten beizutragen. Es ist darüber hinaus möglich, gegebenenfalls – nach einem internen Proposal- und Review-Verfahren – auch neue Properties einzuführen und damit das Datenschema von Wikidata zu erweitern.
Wie sieht es aus mit Wikidata als gemeinsam angereicherte Datenquelle? Hast du hiermit auch schon Erfahrungen gemacht?
Wir haben Wikidata an verschiedenen Stellen mit unseren Daten angereichert: Deskriptoren unseres Standard-Thesaurus Wirtschaft haben wir mit in Wikidata vorliegenden wirtschaftswissenschaftlichen Konzepten verknüpft, um darüber unter anderem Einstiege in unsere Bestandssuche zu schaffen. Zu bekannten, in Wikidata geführten, historischen Persönlichkeiten – darunter auch manche Ökonom:innen – haben wir im Rahmen einer sogenannten „data donation“ Daten und Links auf tausende von Dossiers mit digitalisierten zeitgenössischen Zeitungsartikeln hinzugefügt.
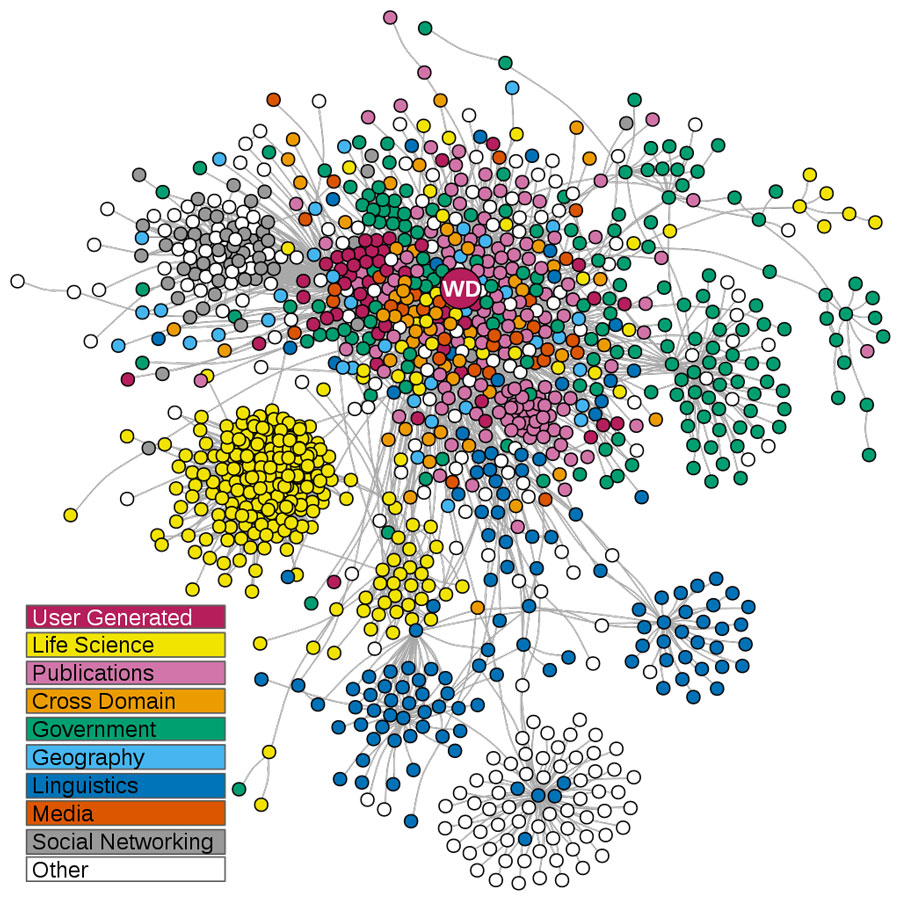
Wikidata in der Linked Open Data Cloud. Datenbanken als
Kreise dargestellt (Wikidata als ‘WD’), mit grauen Linien, die Datenbanken im Netzwerk verbinden, wenn ihre Daten übereinstimmen. (Layout durch graphopt-Algorithmus des igraph-Pakets in [R]. Daten aus folgenden Datasets). Lizensiert unter (CC BY 4.0).
Schließlich haben wir die Informationen zu in Wikidata geführten Wirtschaftsforscher:innen um die insbesondere in dieser Disziplin geläufige RePEc-ID, ferner um die GND-ID, ergänzt. Von letzterem machen wir dann im Rahmen unserer EconBiz-Autor:innenprofile zunächst selbst Gebrauch, wobei diese erweiterten Informationen natürlich auch jederzeit beliebigen Dritten zur Verfügung stehen – und das ist ja letztlich die Idee von transparenter und kollaborativer Wissenschaft im Sinne von Open Science: eigene Erkenntnisse und Arbeitsergebnisse für sich und andere nachnutzbar zu machen.
Beispiele für die Nutzungsszenarien von Wikidata in der Forschung:
Lebenswissenschaften:
- Science Forum: Wikidata as a knowledge graph for the life sciences
- Expansion der Wikidata-Strukturen für Coronaforschung
- Umfassende Datensammlung zu Genom-Informationen
Geisteswissenschaften:
- Using Wikidata to build an authority list of Holocaust-era ghettos
- Archivführer Deutsche Kolonialgeschichte
Wikidata-Verknüpfungen der ZBW:
Beispiele für Verknüpfungen von Wikidata-Items mit STW-Deskriptoren:
Beispiele für Verknüpfungen von Wikidata-Items zu Personen mit Pressematerialien (die Verknüpfung zu ZBW-Daten findet sich jeweils in der Sektion „Identifiers“ als Property „PM20 folder ID“):
Beispiele für EconBiz-Autor:innenprofile, die mit Wikidata ergänzt sind (die Verknüpfung findet sich jeweils am Ende der rechten Infobox zu der Person):
Das könnte Sie auch interessieren:
- Wikimedia 2030: Mit Bibliotheken zur größten Wissensinfrastruktur der Welt
- Digitale Bibliothek: Simulation von Nutzerinteraktionen zur Optimierung der Literaturrecherche
- Softwareentwicklung in Bibliotheken: Von Open Source bis “Not invented here”
- GitHub und “Social Coding”: Neue Formen der Softwareentwicklung und -distribution als Chance
- Forscherprofile in EconBiz: Halbautomatische Generierung mit Linked Open Data
- Bibliotheksmanagementsystem FOLIO: Open Source auf dem Weg in den Bibliotheksalltag
Dieser Artikel ist auch im ZBW-Jahresbericht erschienen, in dem es u.a. um Forschungsdatenmanagement, Open Science und organisiertes Wissen geht: “open” – Der ZBW Jahresrückblick als PDF zum Download.
Dr. Timo Borst ist Leiter der Abteilung Innovative Informationssysteme und Publikationstechnologien bei der ZBW – Leibniz-Informationszentrum Wirtschaft. Er beschäftigt sich mit offenen bibliografischen Daten und Systemen, die ihrer Erzeugung, Verarbeitung, Normierung und Verknüpfung dienen. Dazu zählen sowohl die hauseigenen ZBW-Anwendungen als auch externe Datenhubs wie Wikidata. Er ist auch auf LinkedIn, ORCID, ResearchGate und Twitter zu finden.
Porträt: ZBW©


Jubiläum re3data: 10 Jahre aktiv für die Öffnung von Forschungsdaten und eine Kultur des Teilens

Open Science und der Long-Tail der Wissenschaft: Lasst uns die Lücke überbrücken

European Open Science Cloud: von Einzelprojekten, großen Plänen und 1 Milliarde Euro
View Comments

Open Science Conference 2021: Auf dem Weg zum “New Normal”
Was waren die Schwerpunkte der Open Science Conference 2021? Welche Themen...