
Infografiken über ihren textuellen Inhalt zugänglich machen: Bildersuche neugedacht
Innerhalb von Infografiken in Publikationen schlummern wertvolle Informationen, die bislang nicht direkt gesucht werden können. Ein neuer Ansatz, um Infografiken auffindbar zu machen und damit zugleich einen neuen Zugang zu Publikationen zu schaffen, wurde in der Forschungsgruppe Knowledge Discovery der ZBW entwickelt.
Aus dem ursprünglichen aus textuellen Websites bestehenden Internet ist heutzutage ein multimediales Universum mit den unterschiedlichsten Inhalten geworden. Insbesondere visuelle Inhalte wie Bilder und Videos finden immer mehr Verbreitung. Um diese Inhalte zu finden, bedient man sich jedoch immer noch der konventionellen, text-basierten Suchmaschinen, die umliegende textuelle Inhalte zur Indexierung verwenden. Neuere Verfahren, wie die inverse Bildsuche, befinden sich noch in einem prototypischen Stadium, sind nur Wenigen bekannt und ihre Resultate selten hilfreich.
(Fach-)Bibliotheken verwalten heutzutage auch multimediale Inhalte, denn Publikationen aus Wissenschaft und Forschung sind auch keine rein textuellen Produkte mehr, sondern enthalten beispielsweise Infografiken zur Hervorhebung von Kernaspekten der jeweiligen Forschungsarbeit. Diese werden aber in den seltensten Fällen explizit erfasst, sodass eine Suche nach diesen Grafiken nicht möglich ist, sondern man nach den zugehörigen Publikationen suchen muss. Infografiken bestehen jedoch nicht nur aus grafischen Elementen, sondern enthalten auch Text in den verschiedensten Formaten. Dieser Text kann genutzt werden, um direkt nach Infografiken auf Basis ihrer tatsächlichen Inhalte zu suchen.
Maschinen müssen Infografiken erst verstehen lernen
Die Extraktion dieser Texte aus den binären Bilddateien der Infografiken ist keine triviale Aufgabe und gestaltet sich schwieriger, als man beim Anblick von Infografiken erwarten würde. Diese Diskrepanz lässt sich dadurch erklären, dass Infografiken speziell für das menschliche Auge erstellt werden, ohne Rücksicht auf das maschinelle Verständnis. Die immense Heterogenität der Erscheinungsformen von Infografiken, resultierend aus den subjektiven Vorlieben der Ersteller, der verwendeten Software und anderen Richtlinien, macht die Text-Extraktion zu einer besonderen Herausforderung. Insbesondere die beliebige Rotation von Text-Elementen, neben unterschiedlichen Farbkombinationen und Farbverläufen, Schriftarten und Schriftgrößen sowie Hervorhebungen, machen es schwierig, klassische Verfahren zur Optical Character Recognition (OCR) anzuwenden, um allen Text ohne weitere Vorverarbeitung zu extrahieren. Auch einfache regelbasierte Verfahren versagen bei dieser Komplexität. Abbildung 1 zeigt beispielhaft die Herausforderungen bei der Extraktion von Text.
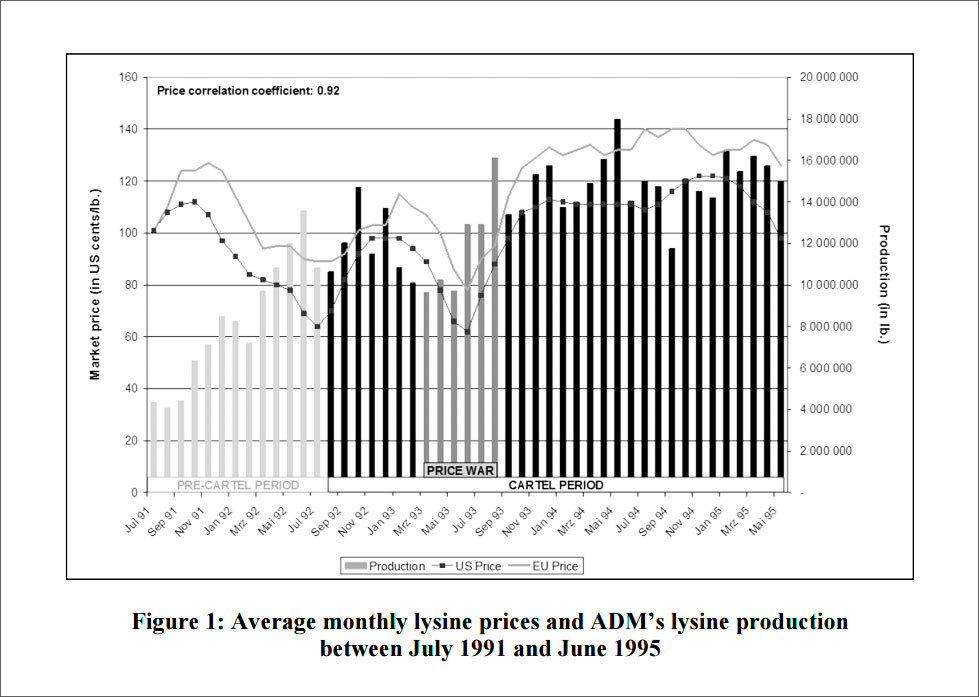 Abbildung 1: Ein Beispiel für eine Infografik mit verschiedenen Herausforderungen aus einem Open Access-Artikel auf EconStor. Quelle: Bueren, Eckart; Hüschelrath, Kai; Veith, Tobias (2014): Time is money – how much money is time? Interest and inflation in competition law actions for damages, ZEW Discussion Papers, No. 14-008, Seite 35
Abbildung 1: Ein Beispiel für eine Infografik mit verschiedenen Herausforderungen aus einem Open Access-Artikel auf EconStor. Quelle: Bueren, Eckart; Hüschelrath, Kai; Veith, Tobias (2014): Time is money – how much money is time? Interest and inflation in competition law actions for damages, ZEW Discussion Papers, No. 14-008, Seite 35
Neues automatisches Verfahren zur Text-Extraktion
Existierende Ansätze fokussieren sich häufig auf spezielle Themengebiete (Domänen) und/oder spezifische Typen von Infografiken. Eine generische Lösung wurde in der Knowledge Discovery-Forschungsgruppe der ZBW entwickelt. Basierend auf der Analyse bestehender semi-automatischer Ansätze zur Text-Extraktion aus Bildern wurde ein automatisches Verfahren entwickelt, das beliebige Texte aus jeder Art von Infografik extrahiert. Das Verfahren lernt keine einzelnen Modelle für die unterschiedlichen Infografiktypen, denn das wären viel zu viele, sondern es wendet eine neuartige Kombination von Methoden aus Bildverarbeitung und Data Mining an, die mit minimaler manueller Eingabe auskommt. Denn nur so ist es möglich, die riesigen Datenmengen zu verarbeiten. Das Verfahren wurde auf mehreren Datensätzen, bestehend aus Infografiken aus verschiedenen Domänen wie Wirtschaftswissenschaften und Chemie, getestet. Die technischen Details sind in den unten aufgeführten Publikationen [1][2] zu finden, die auch auf der Website der Knowledge Discovery-Forschungsgruppe, einschließlich der Datensätze zu finden sind.
Suchmaschinen-Prototyp entwickelt
Im Rahmen des EU-Forschungsprojekts “MOVING” arbeitet die Arbeitsgruppe Knowledge Discovery der ZBW unter Prof. Ansgar Scherp daran, große Datensätze und Dokumente zugänglicher zu gestalten. Als Beitrag zu dieser Vision des Projektes ermöglicht die Text-Extraktion einen verbesserten Zugang zu Infografiken. Um dies zu realisieren, wird die Text-Extraktion in eine praktische Anwendung überführt: Auf Basis der extrahierten Texte aus den Infografiken der Wirtschaftswissenschaften wird eine prototypische Suchmaschine umgesetzt, die Infografiken aus Publikationen, basierend auf ihrem Inhalt, indexiert. Die Suchmaschine besitzt zudem eine Highlight-Funktion, die anzeigt, wo in der Grafik der Suchbegriff gefunden wurde. Auf Mediatalk wurde im Juli 2016 ein Interview mit Prof. Scherp über das Projekt “Moving” veröffentlicht.
Die entwickelte Suchmaschine ist in Abbildung 2 zu sehen. Unter dem Eingabefeld werden einem mehrere Optionen angeboten, beispielsweise ob man nur im Text der Infografiken suchen will, oder ob man auch die Metadaten der umschließenden Publikation mitdurchsuchen will. Außerdem kann man die Ähnlichkeitsfunktion und den Anfragetyp einstellen, da es sich um einen forschungsbasierten Prototypen handelt, bei dem es darum geht, die beste Suchfunktionalität zu ermitteln.
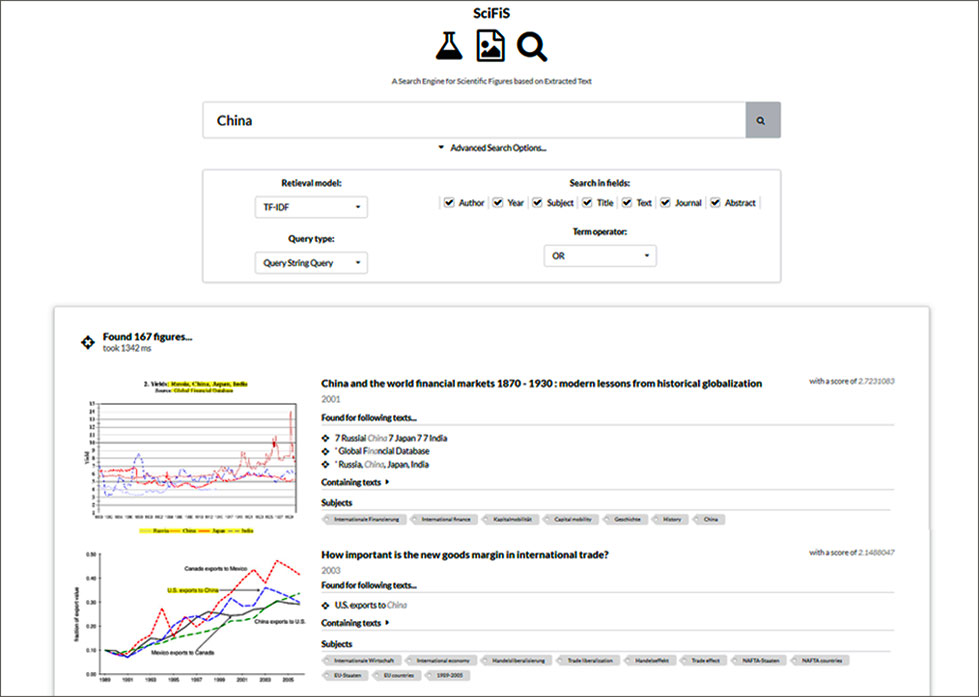 Abbildung 2: Der Suchmaschinen-Prototyp mit den ersten Ergebnissen für die Suchanfrage “China”.
Abbildung 2: Der Suchmaschinen-Prototyp mit den ersten Ergebnissen für die Suchanfrage “China”.
Neue Zugänge zu Infografiken und Publikationen
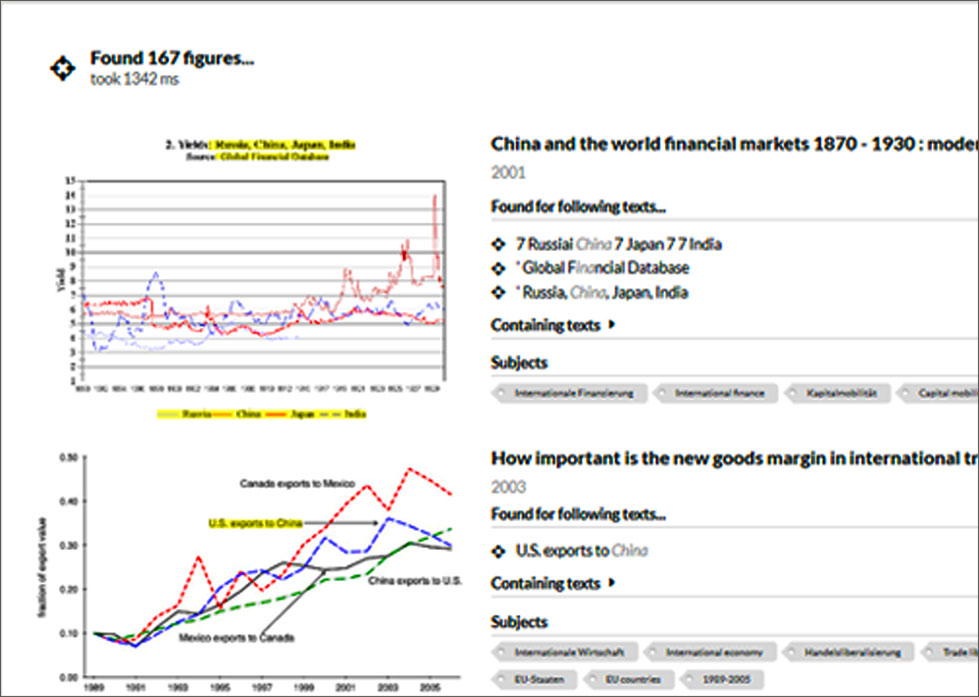
Im unteren Teil der Abbildung 2 sieht man beispielhaft einen Ausschnitt der Trefferliste für die Anfrage “China”. Treffer, die innerhalb des Texts einer Infografik gefunden wurden, werden separat gelistet und in der Infografik selbst explizit mit gelber Farbe hervorgehoben. Dies erleichtert das Verständnis der Infografiken und leitet den Blick direkt auf die gesuchten Inhalte. Zudem werden ein Teil der Metadaten der Publikationen (Titel, Autoren, Jahr, Schlagworte), aus denen die Infografiken stammen, mit angezeigt, um den Kontext der Infografiken zu verdeutlichen. Durch das Anklicken der Infografiken werden diese vergrößert, sodass man diese besser lesen kann. Ein Klick auf den Titel der zugehörigen Publikation leitet einen direkt zur Detailansicht auf EconBiz weiter. Somit werden nicht nur die Infografiken zugänglicher gemacht, sondern auch neue Zugangswege zu den Publikationen, aus denen diese Infografiken stammen, ermöglicht.
Weitere Informationen:
[1] Falk Böschen and Ansgar Scherp. 2015. Multi-oriented Text Extraction from Information Graphics. In Proceedings of the 2015 ACM Symposium on Document Engineering (DocEng ’15). ACM, New York, NY, USA, 35-38. DOI
[2] Falk Böschen and Ansgar Scherp. 2015. Formalization and Preliminary Evaluation of a Pipeline for Text Extraction from Infographics. In Proceedings of the LWA 2015 Workshops: KDML, FGWM, IR, and FGDB. CEUR-WS.org, 2015, 1458, 20-31.
→Autor: Falk Böschen (Wissenschaftlicher Mitarbeiter an der Universität Kiel / ZBW – Leibniz-Informationszentrum Wirtschaft, Forschungsgruppe Knowledge Discovery)


INCONECSS 2019: Ein Blick in die Zukunft wirtschaftswissenschaftlicher Bibliotheken

Open-Science-Studie: Wirtschaftswissenschaften auf Kurs zu mehr Offenheit

#OERcamp 2019: Aus dem Barcamp entwickelt sich die neue Werkstatt für Open Educational Resources
View Comments

Open Science – Kernthema der BMBF-Konferenz zum Europäischen Forschungsraum
Bei der Nationalen Konferenz Europäischer Forschungsraum des Bundesministeriums für...