
Visualisierungen revolutionieren die Recherche: per Anhalter durch die Literatur
Visualisierungen können den Einstieg in neue Wissensdomänen deutlich beschleunigen. Automatisierungsmöglichkeiten vereinfachen nun ihre Erstellung. Bibliothekarinnen und Bibliothekare können dabei eine wichtige Rolle spielen!

In Douglas Adams berühmtem Buch “Per Anhalter durch die Galaxis” wird ein nichtsahnender Mann namens Arthur Dent auf ein Raumschiff gebeamt – zu seinem großen Glück, denn kurz darauf wird die Erde von intergalaktischen Bürokraten zerstört. Mit einer Gruppe von interstellaren Reisenden macht er sich auf den Weg durch das Universum, um die Hintergründe der Zerstörung der Erde zu ergründen. Damit Arthur die seltsamen Phänomene in den Weiten des Weltalls besser verstehen kann, bekommt er den “Hitchhiker’s Guide to the Galaxy” geschenkt, einen Multimedia-Ratgeber, der Wissen und Ratschläge zu allen Themen des Universums bereithält.
Suchmaschine statt Guide für neue Wissensgalaxien
Wenn man ein neues wissenschaftliches Feld ergründet, kann man sich ähnlich wie Arthur Dent fühlen; man ist mit einer neuen Welt konfrontiert, die man erst ordnen und verstehen muss. Leider ist das Wissen nicht in einem einzigen handlichen Ratgeber strukturiert und zusammengefasst, sondern über Millionen wissenschaftlicher Artikel verstreut. Erschwerend kommt hinzu, dass zu Beginn nicht klar ist, welche Artikel überhaupt zu dem Feld gehören und welche davon relevant sind.
Für viele Forschende ist der Ausgangspunkt zur Eroberung einer unbekannten Wissensdomäne die favorisierte Suchmaschine. Dazu wird der Name der Domäne in die Suchmaschine getippt und man beginnt, sich durch die Top-Treffer, zumeist Überblickswerke, zu arbeiten. Nachdem man die ersten Werke gelesen und einige relevante Referenzen daraus recherchiert hat, beginnt man eine Vorstellung für die wichtigsten Themen, Zeitschriften und Autoren in dem Feld zu entwickeln. Darauf aufbauend kann man dann die Suche verfeinern. Genügend Geduld und Zeit vorausgesetzt, kann man sich so ein mentales Modell des Feldes erarbeiten.
 Quelle: Maxi Schramm
Quelle: Maxi Schramm
Trotz hohen Zeiteinsatzes keine Sicherheit
Das Problem an dieser Strategie ist, dass es Wochen, wenn nicht sogar Monate dauert, bis man einen entsprechenden Überblick hat. In vielen Dissertationsprogrammen ist daher das gesamte erste Jahr der Aufarbeitung des State-of-the-Art gewidmet. Dies beinhaltet neben dem Lesen und Zusammenfassen auch viel Sucharbeit. Aber selbst bei der gründlichsten Suchstrategie ist die Chance sehr hoch, ein wichtiges Werk zu verpassen.
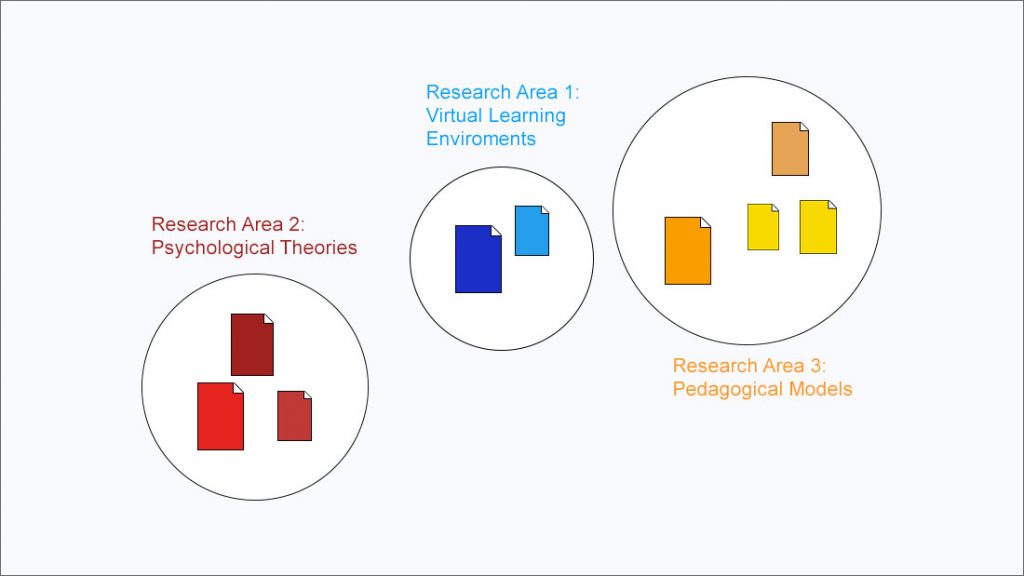
Eine andere Art, um einen Überblick über ein Forschungsfeld zu bekommen, sind Visualisierungen von Wissensdomänen. Ein vereinfachtes Beispiel für eine solche Visualisierung ist weiter oben zu sehen. Sie zeigt die wichtigsten Bereiche in einem Feld und wichtige Artikel zu jedem dieser Bereiche. Auf diese Weise kann ein interessierter Wissenschaftler die intellektuelle Struktur des Feldes auf einen Blick sehen, ohne zahllose Suchanfragen absetzen zu müssen – und ohne auch nur ein einziges Werk gelesen zu haben. Eine weitere Eigenschaft von Visualisierungen von Wissensdomänen ist, dass Bereiche, die sich thematisch ähnlich sind, näher aneinander positioniert werden. Im Beispiel oben sind “Pedagogical Models” thematisch näher an “Virtual Learning Environments” als “Psychological Theories”. So ist es sehr einfach, verwandte Bereiche zum eigenen Interessensgebiet zu finden. Natürlich erspart einem eine solche Visualisierung nicht, die entsprechenden Werke im Anschluss zu lesen – aber man erspart sich eine Menge Zeit, die normalerweise für Suche, Indizierung und Strukturierung verwendet wird.
Visualisierungen bislang meist zu aufwändig
Visualisierungen von Wissensdomänen können nicht nur auf der Ebene von Artikeln erzeugt werden: die untenstehende Visualisierung von Bollen et al. (2009) zeigt die gesamte Wissenschaft auf der Ebene der Zeitschriften. Jeder Knoten entspricht dabei einer Zeitschrift. Die einzelnen Disziplinen werden durch die verschiedenen Farben gekennzeichnet. Obwohl die Idee von Visualisierungen von Wissensdomänen nicht neu ist und trotz ihrer offensichtlichen Nützlichkeit, sind sie zurzeit noch nicht auf breiter Ebene verfügbar. Ein Grund dafür ist, dass die bibliographischen und bibliometrischen Daten, die für eine solche Visualisierung benötigt werden, nur über wenige, sehr teure Quellen zu beziehen sind. Ein weiterer Grund mag sein, dass man sich in der Vergangenheit auf High Level-Visualisierungen konzentriert hat. Diese geben zwar wertvolle Einblicke in die Gesamtstruktur der Wissenschaft , sind aber meist nicht interaktiv und in der täglichen Arbeit damit von wenig Wert, da man hier zumeist bis zu den einzelnen Publikationen vorstoßen möchte. Es gibt einige Tools, um eigene Visualisierungen zu erstellen, allerdings sind sie meist als Werkzeuge für Visualisierungsspezialisten konzipiert und benötigen entsprechende Einarbeitungszeit.

Image credit: Bollen J, Van de Sompel H, Hagberg A, Bettencourt L, Chute R, et al. (2009) Clickstream Data Yields High-Resolution Maps of Science. PLoS ONE 4(3): e4803. Creative Commons Attribution 3.0 Unported
In meiner Forschung habe ich es mir zum Ziel gesetzt, interaktive Visualisierungen zu erstellen, die von jeder und jedem genutzt werden können. Ein Beispiel für eine solche Visualisierung ist weiter unten zu sehen. Hier haben wir exemplarisch das Feld “Educational Technology” strukturiert. Wie in dem dazugehörigen Artikel, “Visualization of Co-Readership Patterns from an Online Reference Management System”, der im renommierten Journal of Informetrics, Kraker et al, 2015, Journal of Informetrics, 9(1), 169–182. doi:10.1016/j.joi.2014.12.003.) erschienen ist, basiert die Visualisierung auf einer neuen Datenquelle: dem Online-Referenzmanagementsystem Mendeley. Die Artikel für die Visualisierung stammen aus Mendeleys Forschungskatalog, der von 2,5 Millionen Nutzern crowd-gesourced wird und Zugriff auf bibliographische und bibliometrische Daten von mehr als 100 Millionen wissenschaftlichen Artikeln bietet.
Co-Readership ermöglicht Rückschluss auf ähnliche Inhalte
Einer der wichtigsten Schritte bei der Erstellung von Visualisierungen von Wissensdomänen ist die Wahl des Ähnlichkeitsmaßes, mit dem die Ähnlichkeit von zwei Artikeln bestimmt wird. Dieses Maß bestimmt, wo ein Artikel in der Visualisierung platziert wird und welchen Abstand er zu den anderen Artikeln hat. Wir verwendeten wieder Daten aus Mendeley, um diese Frage zu beantworten. Im Speziellen verwendeten meine Kolleginnen und Kollegen und ich Co-Readership. Aber was genau ist das? Mendeley ermöglicht es seinen Nutzerinnen und Nutzern, Referenzen in einer persönlichen Bibliothek zu speichern und mit anderen zu teilen. Wie oft ein Artikel in einer persönlichen Bibliothek abgespeichert wird, wird als die Anzahl der Leser (“Reader”) bezeichnet oder kurz Leserschaft (“Readership”). Analog dazu sprechen wir von “Co-Readership”, wenn zwei Artikel zur gleichen Bibliothek hinzugefügt wurden. Wenn Alice Artikel A und Artikel B zu ihrer Bibliothek hinzugefügt hat, dann ist die Co-Readership dieser beiden Artikel gleich 1. Wenn Bob dieselben Artikel zu seiner Bibliothek hinzufügt, dann erhöht sich deren Co-Readership auf 2. Unsere Annahme ist nun, dass eine hohe Co-Readership auch eine hohe Wahrscheinlichkeit für eine thematische Ähnlichkeit darstellt. Dies ist nicht unähnlich zu zwei Büchern, die oft gemeinsam aus einer Bibliothek ausgeliehen werden – es besteht eine gute Chance, dass diese das gleiche oder ein ähnliches Thema behandeln. Wir haben diese Annahme überprüft und unsere Ergebnisse deuten darauf hin, dass sie in der Tat valide ist.
Ähnlichkeitsmaß ermöglicht Automatisierung
Wenn man ein Ähnlichkeitsmaß festgelegt hat, dann kann der Prozess, eine solche Visualisierung zu erzeugen, einfach automatisiert werden. Wir haben dafür Methoden des Clusterings und der Dimensionsreduktion verwendet. Wir haben auch einen Algorithmus auf der Basis der Text Mining APIs OpenCalais und Zemanta entwickelt, der einen Vorschlag zur Bezeichnung der Forschungsbereiche liefert.
Die resultierende Visualisierung ist unten zu sehen. Die blauen Blasen repräsentieren die wichtigsten Forschungsbereiche. Die Größe der Blasen zeigt an, wie oft die Publikationen in diesem Bereich gelesen wurden. Je näher sich zwei Bereiche in der Visualisierung sind, desto höher ist ihre thematische Ähnlichkeit. Rechts werden die Metadaten noch einmal in Listenform angezeigt. Die Visualisierung ist interaktiv: wenn man auf eine Blase klickt, dann sieht man die am meisten gelesenen Publikationen in diesem Bereich. Eine Version, die die ersten 100 Ergebnisse einer Suche in PLOS visualisiert, kann auf Open Knowledge Map gefunden werden. Auch der Source Code ist auf Gitub verfügbar.
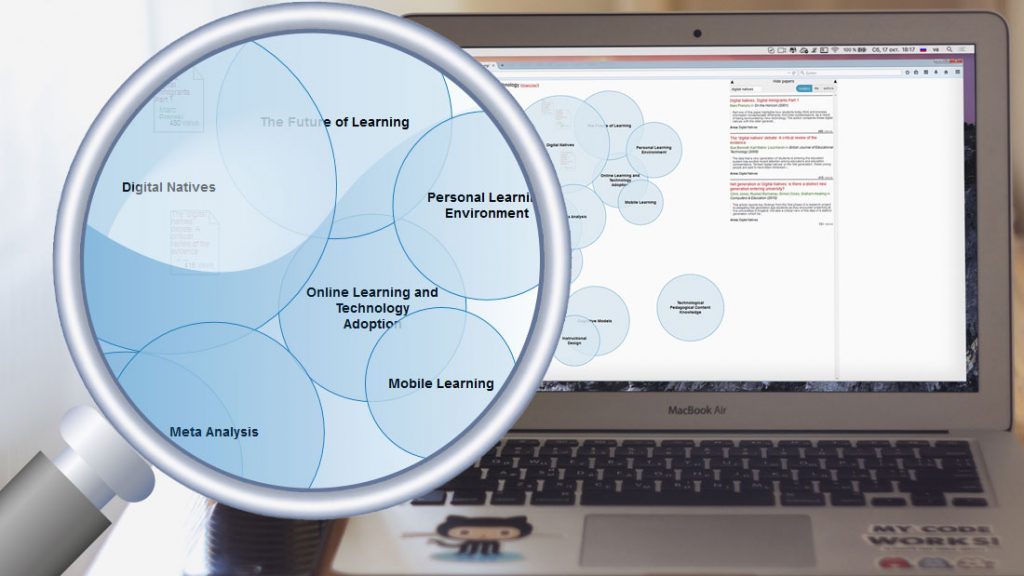
Neben der Tatsache, dass man einen schnellen Überblick über ein Feld bekommen kann, gibt es noch weitere interessante Dinge, die man von einer solchen Visualisierung lernen kann. Fisichella et al. (2009) argumentieren, dass man dadurch sogar der Fragmentierung von Forschungsbereichen entgegenwirken kann, da die Forschenden so einen Einblick in die einzelnen Communities bekommen können. Es mag eine gewisse Wahrheit in dieser Annahme liegen. Bei der Evaluierung der Visualisierung mit Forschenden aus dem Bereich zeigte sich, dass einzelne Forschende bestimmte, stark spezialisierte Forschungsbereiche wie “Technological Pedagogical Content Knowledge” nicht kannten.
Veränderungen von Wissensgebieten nachvollziehen
Eine weitere interessante Anwendung von Visualisierungen ist, die Entwicklung eines Feldes zu studieren. Beim Vergleich mit ähnlichen Visualisierungen basierend auf älterer Literatur (zum Beispiel Cho et al. 2012) zeigte sich, dass Felder wie Learning Environments, die eine wichtige Rolle in den 2000er-Jahren spielten, später in verschiedene Bereiche aufgesplittet wurden (etwa Personal Learning Environments, Game-based Learning). Weitere Beispiele können dem Paper “Educational Technology as Seen Through the Eyes of the Readers” im Journal of Infometrics, 9(1), 169–182. Kraker, P., Schlögl, C., Jack, K., & Lindstaedt, S. (2015) doi:10.1016/j.joi.2014.12.003. entnommen werden.
Bibliotheken erschaffen den „Anhalter“ für unendliche Wissensgalaxien
Welche Rolle können nun Bibliothekarinnen und Bibliothekare beim Aufbau dieser Visualisierungen spielen? Nun, auch wenn ich weiter oben geschrieben habe, dass die Visualisierungen weitestgehend automatisiert werden können, hat sich doch gezeigt, dass es dabei zwei Probleme gibt: zum einen kommt es immer wieder zu Fehlzuordnungen und Fehlbenennungen; diese lassen sich bei algorithmischen Verfahren nie ganz vermeiden. Zum anderen haben die Charakteristiken der Leser einen Einfluss auf das Ergebnis. Im konkreten Fall waren die Leserinnen hauptsächlich aus dem Bereich der Pädagogik, wodurch einige informatisch geprägte Forschungsbereiche fehlten.
Daraus ergibt sich, dass diese Visualisierungen nach der Erstellung einer Überprüfung bedürfen – und wer könnte dafür besser geeignet sein als die Informationsstrukturierungs- und Klassifikationsspezialistinnen und -spezialisten aus Bibliotheken. Die Idee wäre, dass Bibliothekarinnen und Bibliothekare gemeinsam mit einer interessierten Community die vorberechneten Visualisierungen prüfen, adaptieren und wieder teilen. So kann neben den bereits bestehenden Plattformen, die Content bereitstellen, auch ein globales System entstehen, in dem diese Inhalte kollaborativ strukturiert werden. Erst dadurch werden die Visualisierungen zu jenem universellen „Anhalter“, mit dem sich Studierende und Forschende in die unendlichen Weiten der Wissenschaft wagen können. Denn eines ist sicher: die Menge an wissenschaftlicher Information, die jeden Tag veröffentlicht wird, steigt stetig und es ist kein Ende in Sicht. Geben wir Studierenden und Forschenden ein neues Werkzeug in die Hand, mit dem diese den Überblick über ihre Studien- und Forschungsgebiete bekommen und auch über längere Zeit behalten können.
 → Autor: Dr. Peter Kraker ist Postdoc am Forschungszentrum Know-Center im Bereich Social Computing. In seiner Forschung beschäftigt er sich mit den Themen Altmetrics, Open Science und der Visualisierung wissenschaftlicher Kommunikation im Netz.
→ Autor: Dr. Peter Kraker ist Postdoc am Forschungszentrum Know-Center im Bereich Social Computing. In seiner Forschung beschäftigt er sich mit den Themen Altmetrics, Open Science und der Visualisierung wissenschaftlicher Kommunikation im Netz.


ZBW nimmt Usability Lab in Betrieb

Toolsammlungen: Die passenden Tools für digitale Zusammenarbeit und Lernen auswählen

Open Science und Organisationskultur: Offenheit als Kernwert in der ZBW
View Comments

Jodel – Anonymer Campus-Talk: Trash oder neues Twitter?
Jodel ist eine seit Oktober 2014 kostenlos erhältliche App für Android und iOS. Hier...