
AI in Academic Libraries, Part 2: Interesting Projects, the Future of Chatbots and Discrimination Through AI
What are currently the most interesting AI projects in libraries and infrastructure institutions? Why are chatbots so promising as a field where artificial intelligence can be deployed? How can we prevent AI-based systems from making decisions that discriminate? Is this relevant in a library context at all? The second part of the three-part interview series with Anna Kasprzik and Frank Seeliger focuses on these questions.
Interview with Frank Seeliger (TH Wildau) and Anna Kasprzik (ZBW)

We recently had an intense discussion with Anna Kasprzik (ZBW) and Frank Seeliger (Technical University of Applied Sciences Wildau – TH Wildau) on the use of artificial intelligence in academic libraries. Both of them were recently involved in two wide-ranging articles: “On the promising use of AI in libraries: Discussion stage of a white paper in progress – part 1” (German) and “part 2” (German).
Dr Anna Kasprzik coordinates the automation of subject indexing (AutoSE) at the ZBW – Leibniz Information Centre for Economics. Dr Frank Seeliger (German) is the director of the university library at the Technical University of Applied Sciences Wildau and is jointly responsible for part-time programme Master of Science in Library Computer Sciences (M.Sc.) at the Wildau Institute of Technology.
This slightly shortened, three-part series has been drawn up from our spoken interview. These two articles are also part of it:
- Part 1: Areas of Activity, Big Players and the Automation of Indexing
- Part 3: Prerequisites and Conditions for Successful Use
What are currently the most interesting AI projects in libraries and infrastructure institutions?
Anna Kasprzik: Of course, there are many interesting AI projects. Off the top of my head, the following two come to mind: The first one is interesting for you if you are interested in the issue of optical character recognition (OCR). Because, before you can even start to think about automated subject indexing, you have to create metadata, i.e. “food” for the machine. So to speak: segmenting digital texts into their structural fragments, extracting an abstract automatically. In order to do this, you run OCR on the scanned text. Qurator (German) is an interesting project in which machine learning methods are used as well. The Staatsbibliothek zu Berlin (Berlin State Library) and the German Research Center for Artificial Intelligence (DFKI) are involved, among others. This is interesting because at some point in the future it might give us the tools we need in order to be able to obtain the data input required for automated subject indexing.
The other project is the Open Research Knowledge Graph (ORKG) of the TIB Hannover. The Open Research Knowledge Graph is a way of representing scientific results no longer as a document, i.e. as a PDF, but rather in an entity-based way. Author, research topic or method – all nodes in one graph. This is the semantic level and one could use machine learning methods in order to populate it.
Frank Seeliger: Only one project: it is running at the ZBW and the TH Wildau and explores the development of a chatbot with new technologies. The idea of chatbots is actually relatively old. A machine conducts a dialogue with a human being. In the best case, the human being does not recognise that a machine is running in the background – the Turing Test. Things are not quite this advanced yet, but the issue we are all concerned with is that libraries are being consulted – in chat rooms, for example. Many libraries aim to offer a high level of service at the times when researchers and students work, i.e. round the clock. This can only take place if procedures are automated, via chatbots for example, so that difficult questions can be also answered outside the opening hours, at weekends and on public holidays.
I am therefore hoping firstly that the input we receive concerning chatbot development means that it will become a high-quality standard service that offers fast orientation and gives information with excellent predictive quality about a library or special services. This would create the starting point for other machines such as moving robots. Many people are investing in robots, playing around with them and trying out various things. People are expecting that they will be able to go to them and ask, “Where is book XY?” or “How do I find this and that?”, and that these robots can deal with such questions profitably and show “there’s that” in an oriented way and point their finger at it. That’s one thing.
The second thing that I find very exciting for projects is to win people over to AI at an early stage. Not just to save AI as a buzzword, but to look behind the scenes of this technology complex. We tried to offer a certificate course (German). However, demand has been too low for us to offer the course. But we will try it again. The German National Library provides a similar course that was well attended. I think it’s important to make a low-threshold offer across the board, i.e. for a one-person library or for small municipal libraries that are set up on a communal basis, as well as for larger university libraries. That people get to grips with the subject matter and find their own way, where they can reuse something, where there are providers or cooperation partners. I find this kind of project is very interesting and important for the world of libraries.
But this too can only be the starting point for many other offers of special workshops, on Annif for example or other topics that can be discussed at a level that non-informaticians can understand as well. It’s an offer to colleagues who are concerned with it, but not necessarily at an in-depth level. As with a car – they don’t manufacture the vehicle themselves, but want to be able to repair or fine-tune it sometimes. At this level, we definitely need more dialogue with the people who are going to have to work with it, for example as system administrators who set up or manage such projects. The offers must also be focused towards the management level – the people who are in charge of budgeting, i.e. those who sign third-party funding applications.
At both institutions, the TH Wildau and the ZBW, you are working on the use of chatbots. Why is this AI application area for academic libraries so promising? What are the biggest challenges?
Frank Seeliger: The interesting perspective for me is that we can operate the development of a chatbot together with other libraries. It is nice when not only one library serves as a knowledge base in the background for the typical examples. This is not possible with locally specific information such as opening hours or spatial conditions. Nevertheless, many synergy effects are created. We can bring them together and be in a position to generate as large a quantity of data as possible, so that the quality of the assertions that are automatically generated is simply better than if we were to set it up individually. The output quality has a lot to do with the data quality. Although it is not true that the more data, the better the information. Other factors also play a role. But generally, small solutions tend to fail because of the small quantity of data.
Especially in view of the fact that a relatively high number of libraries are keen to invest in robot solutions that “walk” through the library outside the opening hours and offer services, like the robot librarian. If the service is used, it therefore makes twice as much sense to offer something online, but also to retrieve it using a machine that rolls through the premises and offers the service. This is important, because the personal approach from the library to the clients is a very decisive and differentiating feature as opposed to the large meta levels that offer their services in the commercial field. Looking for dialogue and paying attention to the special requirements of the users: this is what makes the difference.
Anna Kasprzik: Even though I am not involved in the chatbot project at ZBW, I can think of three challenges. The first is that you need an incredible amount of training data. Getting hold of that much data is relatively difficult. Here at ZBW we have had a chat feature for a long time – without a bot. These chats have been recorded but first they had to be cleaned of all personal data. This was an immense amount of editorial work. That is the first challenge.
The second challenge: it’s a fact that relatively trivial questions, such as the opening hours, are easily answered. But as soon as things become more complex, i.e. when there are specialised questions, you need a knowledge graph behind the chatbot. And setting this up is relatively complex.
Which brings me to the third challenge: during the initial runs, the project team established that quite a few of the users had reservations and quickly thought, “It doesn’t understand me”. So there were reservations on both sides. We therefore have to be mindful of the quality aspect and also of the “trust” of the users.
Frank Seeliger: But the interactions also follow the direction of speech, particularly from the younger generations who are now coming through as students in the libraries. This generation communicates via voice messages: the students speak with Siri or Alexa and they are informal when speaking to technologies. FIZ Karlsruhe has attempted to define search queries using Alexa. That went well in itself, but it failed because of the European General Data Protection Regulation (GDPR), the privacy of information and the fact that data was processed somewhere in the USA. Naturally, that is not acceptable.
That’s why it is good that libraries are doing their own thing – they have data sovereignty and can therefore ensure that the GDPR is maintained and that user data is treated carefully. But it would be a strategic mistake if libraries did not adapt to the corresponding dialogue. Very simply because a lot of these interactions no longer take place with writing and reading alone, but via speech. As far as apps and features are concerned, much is communicated via voice messages, and libraries need to adapt to this fact. It starts with chatbots, but the question is whether search engines will be able to cope with (voice) messages at some point and then filter out the actual question. Making a chatbot functional and usable in everyday life is only the first step. With spoken language, this then incorporates listening and understanding.
Is there a timeframe for the development of the chatbot?
Anna Kasprzik: I’m not sure, when the ZBW is planning to put its chatbot online; it could take one or two years. The real question is: when will such chatbots become viable solutions in libraries globally? This may take at least ten years or longer – without wanting to crush hopes too much.
Frank Seeliger: There are always unanticipated revivals popping up, for which a certain impetus is needed. For example, I was in the IT section of the International Federation of Library Associations and Institutions (IFLA) on statistics. We considered whether we could determine statistics clearly and globally, and depict them as a portfolio. Initially it didn’t work – it was limited to one continent: Latin America. Then the section received a huge surprise donation from the Bill and Melinda Gates Foundation and with it, the project IFLA Library Map of the World could be implemented.
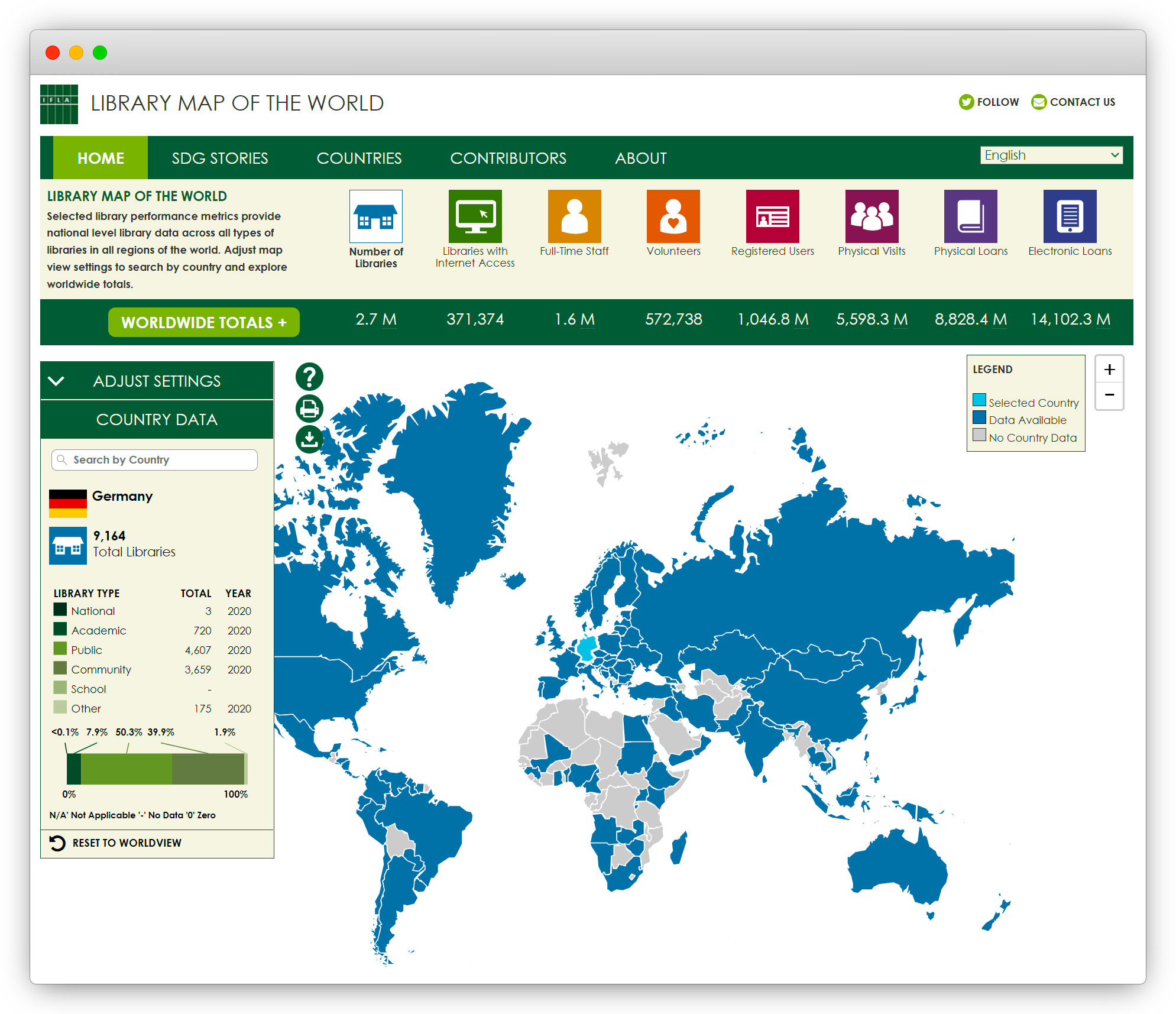
It was therefore a very special impetus that led to something that we would normally not have achieved with ten years’ work. And when this impetus exists through tenders, funding, third-party donors that accelerate exactly this kind of project, perhaps also from a long-term perspective, the whole thing takes on a new dynamic. If the development of chatbots in libraries continues to stagnate like this, they will not use them on a market-wide scale. There was also a movement with contactless object recognition via radio waves (Radio-Frequency Identification, RFID). It started in 2001 in Siegburg, then Stuttgart and Munich. Now, it is used in 2,000 to 3,000 libraries. I don’t see this impetus with chatbots at all. That’s why I don’t think that, in ten or 15 years, chatbots will be used in 10% to 20% of libraries. It’s an experimental field. Maybe some libraries will introduce them, but it will be a handful, perhaps a dozen. However if a driving force occurs owing to external factors such as funding or a network initiative, the whole concept may receive new momentum.
The fact that AI-based systems make discriminatory decisions is often regarded as a general problem. Does this also apply to the library context? How can this be prevented?
Anna Kasprzik: That’s a very tricky question. Not many people are aware that potential difficulties almost always arise from the training data because training data is human data. These data sources contain our prejudices. In other words, whether the results may have a discriminating effect or not depends on the data itself and on the knowledge organisation systems that underpin it.
One movement that is gathering pace is known as de-colonisalisation. People are therefore taking a close look at the vocabularies they use, thesauri and ontologies. The problem has come up for us as well: since we also provide historical texts, terms that have racist connotations today appeared in the thesaurus . Naturally, we primarily incorporate terms that are considered politically correct. But these definitions can shift over time. The question is: what do you do with historical texts where this word occurs in the title? The task is then to find different ways to provide them as hidden elements of the thesaurus but not to display them in the interface.
There are knowledge organisation systems that are very old and have developed in times very different from ours. We need to restructure them completely as a matter of urgency. It’s always a balancing act if you want to display texts from earlier periods with the structures that were in use at that time. Because I must both not falsify the historical context, but also not offend anyone who wants to search in these texts and feel represented or at least not discriminated against. This is a very difficult question, particularly in libraries. People often think: that’s not an issue for libraries, it’s only relevant in politics, or that sort of thing. But on the contrary, libraries reflect the times in which they exist, and rightly so.
Frank Seeliger: Everything that you can use can also be misused. This applies to every object. For example, I was very impressed in Turkey. They are working with a big Koha approach (library software), meaning that more than 1,000 public libraries are using the open source solution Koha as their library management software. They therefore know, among other things, which book is most often borrowed in Turkey. We do not have this kind of information at all in Germany via the German Library Statistics (DBS, German). This doesn’t mean that this knowledge discredits the other books, that they are automatically “leftovers”. You can do a lot with knowledge. The bias that exists with AI is certainly the best known. But it is the same for all information: should monuments be pulled down or left standing? We need to find a path through the various moral phases that we live through as a society.
In my own studies, I specialised in pre-Colombian America. To name one example, the Aztecs never referred to themselves as Aztecs. If you searched in catalogues of libraries pre-1763, the term “Aztec” did not exist. They called themselves Mexi‘ca. Or we could take the Kerensky Offensive – search engines do not have much to offer on that. It was a military offensive that was only named that afterwards. It used to be called something else. It is the same challenge: to refer to both terms, even if the terminology has changed, or if it is no longer “en vogue” to work with a certain term.
Anna Kasprzik: This is also called concept drift and it is generally a big problem. It’s why you always have to retrain the machines: concepts are continually developing, new ones emerge or old terms change their meaning. Even if there is no discrimination, terminology is constantly evolving
.
And who does this work?
Anna Kasprzik: The machine learning experts at the institution.
Frank Seeliger: The respective zeitgeist and its intended structure.
Thank you for the interview, Anna and Frank.
Part 1 of the interview on “AI in Academic Libraries” is about areas of activity, the big players and the automation of indexing.
Part 3 of the interview on “AI in Academic Libraries” focuses on prerequisites and conditions for successful use .
This text has been translated from German.
This might also interest you:
- On the Promising Use of AI in Libraries: Discussion Status of a White Paper in Progress – Part 1 and Part 2 (both in German)
- Establishment of a Productive Service for Automated Content Indexing at the ZBW – a Status and Experience Report (German), presentation slides from the Library Congress in Leipzig
- Get everybody on board and get going – the automation of subject indexing at ZBW (PDF), presentation slides by Anna Kasprzik from the IFLA Satellite Event „New Horizons on Artificial Intelligence in Libraries“
- Automating subject indexing at ZBW – the costs of the digital transformation and why we need less projects, presentation slides from the LIBER Conference 2022
- 14th Wildau Library Symposium on 13. & 14. September 2022, including “Best of Failure” (German)
- On the working focus “Automation of subject indexing using methods from artificial intelligence“ of the ZBW
- Discrimination Through AI: To What Extent Libraries are Affected and how Staff Can Find the Right Mindset
- Libraries: Books in Clouds (German)
- Artificial Intelligence: New Opportunities for Citizen Science, Research and Libraries
- Science Checker: Open Access and Artificial Intelligence Help Verify Claims
- Digital Open Science Tools: How to Achieve More Openness Through an Inclusive Design
- Horizon Report 2020: AI, XR and OER Begin to Catch on in Higher Education
- DGI Day Practicum: How Does Artificial Intelligence Change the World of Information Professionals?
- Hackathon Coding.Waterkant: How to Improve Library Services Through Chatbots and Artificial Intelligence
- Revival of Chatbots: Revolution of Customer Contact, Disruption of the Software Market?
- Google Engineer Put on Leave After Saying AI Chatbot has Become Sentient
Dr Anna (Argie) Kasprzik, coordinator of the automation of subject indexing (AutoSE) at the ZBW – Leibniz Information Centre for Economics. Anna’s main focus lies on the transfer of current research results from the areas of machine learning, semantic technologies, semantic web and knowledge graphs into productive operations of subject indexing of the ZBW. You can also find Anna on Mastodon.
Portrait: ZBW©, photographer: Carola Gruebner
Dr Frank Seeliger (German) has been the director of the university library at the Technical University of Applied Sciences Wildau since 2006 and has been jointly responsible for the part-time programme part-time programme Master of Science in Library Computer Sciences (M.Sc.) at the Wildau Institute of Technology since 2015. One module explores AI. You can find Frank on ORCID.
Portrait: TH Wildau
Featured Image: Alina Constantin / Better Images of AI / Handmade A.I / Licensed by CC-BY 4.0


Science Checker: Open Access and Artificial Intelligence Help Verify Claims

Waterkant Festival 2018: A Model for Learning and Working 4.0

Open Economics Guide: New Open Science Support for Economics Researchers
View Comments
AI in Academic Libraries, Part 1: Areas of Activity, Big Players and the Automation of Indexing
What are the most promising areas of activity for the use of artificial intelligence...