
Barcamp Open Science 2021: Opening up New Perspectives
"Almost as good as 'the real one'" was the feedback of one contributor on the seventh Barcamp Open Science, which for the first time was held completely online and thus not as usual at Wikimedia Germany offices in Berlin. Together with some session moderations, we give an insight into what was going on at this year's Barcamp.
by Sonja Bayer, Tim Boxhammer, Axel Dürkop, Florian Hagen, Emma Anne Harris, Lambert Heller, Juliane Kant, Peter Kraker, Albert Krewinkel, Felicitas Kruschick, Thomas Lösch, Isabella Meinecke, Guido Scherp, Stefan Skupien, Antonella Succurro, Klaus Thoden, Michela Vignoli, Simon Worthington and Philipp Zumstein
This year again, on 16 February , the Leibniz Research Alliance Open Science and Wikimedia Germany invited to the annual Barcamp Open Science (#oscibar) as a pre-event of the Open Science Conference. Due to the pandemic, the Barcamp was held completely online for the first time and we were able to gather around 100 contributors who discussed a wide range of topics related to Open Science.
A general observation of the last years could be confirmed this year: about half of the contributors had been to a Barcamp Open Science before, for the other half it was their first participation (and for further half of them it was their first Barcamp ever). We were pleased that we could once again attract more people to a new format to enable them to exchange with each other and grow an established Open Science community.
Compared to the Barcamps Open Science of previous years, this barcamp further especially showed that many sessions were already planned and well prepared in advance. However, the conducted sessions were not really about Open Science in pandemic times, which would have been obvious. But the range of topics is constantly expanding, not least due to this year’s Ignition Talk by Felicitas Kruschick on the topic “Knowledge Inequity & Open Science”, for which she also offered a session. For this blog post, she and the other session moderators have collected highlights and most interesting insights from the Barcamp Open Science.
Privacy preserving Open Data
by Antonella Succurro

Privacy preserving Open Data
by Antonella Succurro
The Horizon2020 guidelines on FAIR (Findable, Accessible, Interoperable and Reusable) data (PDF) states that data should be “As open as possible, as closed as necessary”. When it comes to sensitive data it is then up to the individual researchers or institutes to decide how to “open” them: they can opt for a very conservative approach (not share at all) or develop creative and innovative ways to share sensitive information. Common privacy preserving data sharing practices include data anonymisation and data aggregation, but both approaches can present challenges. In the first case, there is a risk of de-anonymisation through, for example, cross-referencing with additional data. In the second case, the more aggregated statistics are gathered, the higher the chance that some information gets identified.
This session highlighted how the support from data privacy officers or external trustees is often not sufficient to face the challenges of highly specific data, which might come from new technologies and have yet to be standardized. For example, genomics data are considered impossible to anonymise without losing the biological value for research purposes. We hence need a coordinated effort to build infrastructures providing training and services for harmonised data sharing “best practices” within the legal framework of the General Data Protection Regulation (GDPR).
Session Pad
Open Knowledge Maps Custom Services
by Peter Kraker and Michela Vignoli

Open Knowledge Maps Custom Services
by Peter Kraker and Michela Vignolio
Today we are facing a discoverability crisis that makes it hard to stay on top of the latest research. Open Knowledge Maps (OKMaps) is an open visual discovery tool based on knowledge maps that supports researchers, students and practitioners searching for relevant scientific knowledge. As a community-driven organisation, OKMaps involves the broader user community from early on in the development phase.
In this spirit, the OKMaps team invited the Barcamp Open Science participants to discuss early ideas for the brand new ‘custom services’ of OKMaps. The customisable cloud services will be embedded in libraries’ discovery services to add instant visual capabilities. The session participants reacted positively to this concept and suggested additional interesting use cases. One was to integrate knowledge maps with institutional researcher profiles to add a visual presentation of authored publications. Another proposition was to use knowledge maps to display reading suggestions for students to have a more clearly arranged alternative to confusingly long lists.
The input provided by the community helps the OKMaps team immensely to shape the custom services design according to user needs. The custom services are funded through the Open Knowledge Maps supporting membership programme. Supporting member organisations are directly involved in the decision-making process of Open Knowledge Maps. More information on the programme can be found on the OKMaps website. Please contact us if you want to get involved via email to info (at) openknowledgemaps.org or via Twitter @OK_Maps
Session Pad
Knowledge Inequity & Open Science criteria as a way out of it?
by Felicitas Kruschick

Knowledge Inequity & Open Science criteria as a way out of it?
by Felicitas Kruschick
Is Open Science automatically leading to Knowledge Equity? We discussed this question and found out that it is not that easy. Everyone needs to constantly reflect on the power dynamics in which everyone has to analyse and discuss their project and work (which was considered not that easy due to time e.g.). Who is benefitting how from projects and who is not? Who is leading through theoretical discourses and why? Whose voices are being heard and whose are staying silent and why? Everyone needs to ask themselves: Who is left behind and in which way? Only if everyone continuously reflects on those questions leading to different answers for different contexts and realities everyone is able to face the challenge of Knowledge Equity.
The question of addressing must never be forgotten. Who is addressing whom in which context? Who is meant by ‘we’ and who by ‘the others’? If one thinks of Said’s theory of Orientalism (2003), it becomes obvious that the question of knowledge inequity can only be posed in the context of power, which has direct consequences for the addressing of the ‘other’. Whether in the context of science and research, politics or economics, internationally or locally – when a ‘we’ is assumed, an ‘other’ is manifested, which can have the effect of reinforcing injustice at the manifest level. One of the main outcomes of the session was therefore that one should never stop asking oneself what position one holds in which context and who is being downgraded at the same time. But what emerged as equally undoubted was that the question of knowledge injustice must be seen as a dilemma, as it can never be fully achieved.
A second important point was the question of why science and research do not ‘work’ more with Open Science criteria. It was noted that science is perceived as being stuck in ‘old’ infrastructures. It takes effort and courage to break down these old beliefs, which in our opinion are based on financial aspects and reputation, but also a great deal of uncertainty about the maintainability of scientific quality, and to introduce new ideas. We have also found out that Open Science affinity probably differs from department to department. In social science disciplines, the use of Open Science is less established, as the argument of sensitive data is often used here.
Session Pad
Further Readings:
(Re-)using available research data in the social, educational,
behavioural and economic sciences
by Thomas Lösch and Sonja Bayer

(Re-)using available research data in the social, educational, behavioural and economic sciences
by Thomas Lösch and Sonja Bayer
(Re-)using available research data means that research data provided for example by research data centers is used in a way that was not necessarily intended while the data was being collected. (Re-)using data has many advantages as it realises the potential of Open/FAIR data by making good use of available resources.
The session was intended to get an overview of what the current state is. Is data used? What works, what doesn’t and why?
We mainly identified barriers and some enablers for (re-)using research data:
- Research data needs to be well-documented so (re-)users can see how the data was created – especially with regard to nuances in different labs or communities (for example, slightly different ways to measure the same thing). This is even more relevant for an interdisciplinary (re-)use of available data.
- A centralised point of access to research data helps researchers a lot in finding useful data – for example, this is the case in astrophysics.
- Policies of funders as well as application procedures should allow the (re-)use of data as a standard possibility.
- Moreover, funders can foster data reuse by including it in their materials. For example, grant application forms could explicitly require a statement about which available data will be used (or why new data needs to be collected). Also, funders could directly point to trustworthy repositories.
- In scientific communities, (re-)using data is often not valued as much as collecting data yourself. Sometimes, it is seen as more innovative to collect data in an amazing new way.
An opportunity to dive deeper into the topic might be in September 2021, where we plan to organise a barcamp dedicated to the topic of (re-)using research data.
Session Pad
How to support Open Scientists within your university?
by Philipp Zumstein

How to support Open Scientists within your university?
by Philipp Zumstein
Supporting researchers with access to information or providing them with hardware and software are traditional services for libraries or IT service units within a university or other institutions. When researchers are practicing Open Science they may have further needs for support and that was the topic of this session.
As a result of some quick starting questions among the participants, we see some hints of which aspects of Open Science support are important and how much support is currently there:

There are several areas of Open Science for which institutional support may be lacking. It was discussed that responsibilities within an institution (for example: for Open Access it should be the library) are crucial for establishing Open Science services. Thus, the question is also, for example: Who is responsible for supporting Open Scientists with preregistration of studies? Any strategic plans for a university should also consider the subject-specific needs from their researcher areas. Many more things were touched upon in this fruitful discussion and helpful links were given. For further details have a look at the session pad.
Session Pad
Discussing Approaches of Single Source Publishing in
Research and Education | Community Networking
by Tim Boxhammer, Axel Dürkop, Florian Hagen, Albert Krewinkel,
Isabella Meinecke, Klaus Thoden, and Simon Worthington
Approaches of Single Source Publishing in Research and Education | Community Networking
by Tim Boxhammer, Axel Dürkop, Florian Hagen, Albert Krewinkel, Isabella Meinecke, Klaus Thoden, and Simon Worthington
The aim of our session was to network stakeholders from the Open Science community that are actively working on or are highly interested in Single Source Publishing (SSP). SSP allows producing diverse output formats (for example: HTML, PDF, JATS/XML) from only a single source (for example: Markdown or XML). Three approaches – briefly listed below – were introduced and discussed. Newcomers and experts defined the benefits of SSP focussing on the different aspects of the research lifecycle.
In the session three projects were presented:
- At TIB Open Science Lab, Simon Worthington and colleagues are working on semantic publishing for architecture where they try to pull together a variety of data sources and complex digital objects into a textbook publication. The research context is in the German consortium of the National Research Infrastructure for Culture (NFDI4Culture) where a consortium brings together advanced open infrastructures, for example: knowledge graphs, IIIF deep image zoom, Wikidata, and PID use in 3D point clouds and video.
See also the GitHub repo: ADA – Semantic Publishing. - Klaus Thoden presented the Edition Open Access Publication Infrastructure, which uses TEI-XML as the main document format for its SSP workflows. He stressed that in SSP it is important to ensure that the source format is the richest format. That is, it will contain all the necessary mark-up and metadata. The final publication formats like PDF, EPUB or an online version are created from that source, and they can be considered lossy versions that simply serve their special purpose.
- Axel Dürkop finally gave a short introduction to Swapfire, an approach by Hamburg University of Technology (TUHH) and Hamburg State and University Library. It is a modular framework developed within the project Modern Publishing that consists of GitLab and Open Journal Systems (OJS), supported by pandoc/pandoc-scholar (multi-format converter) and hypothes.is (annotate). The framework is an effective and highly customisable approach to produce diverse output formats from a single source.
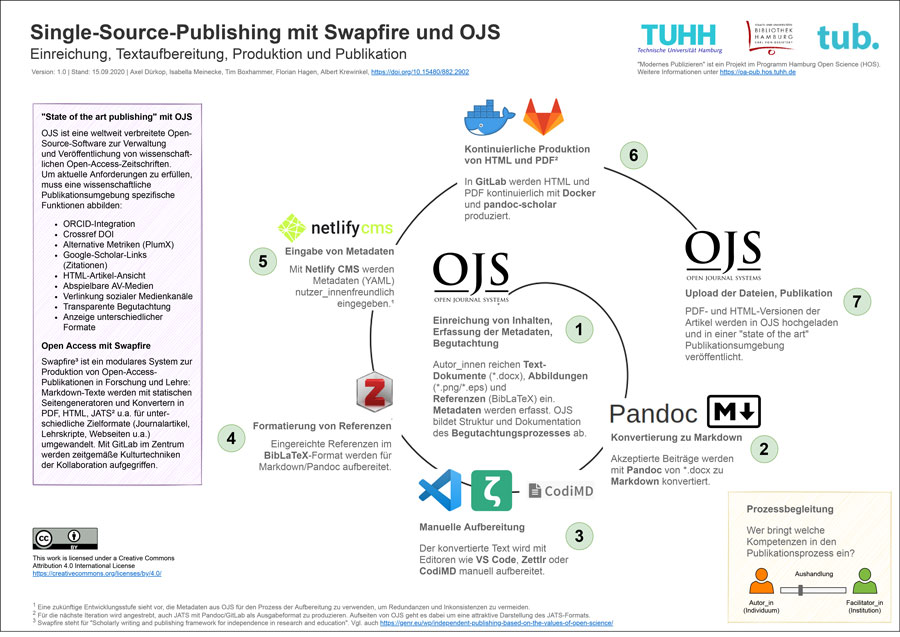
Darstellung eines Workflows für Single-Source-Publishing mit Markdown, Gitlab, pandoc und OJS. (CC BY 4.0).
The short presentations were followed by a discussion of the participants. A wish was expressed to have more hands-on material to get started. Finally, the idea to build a community on SSP was supported.
How to participate in the future? Contact: email to oa-pub.hos(at)tuhh.de or take a look at the session pad.
Session Pad
At Your (Data) Service: How Can We Expand
Research Data Management 'Service Portfolios'
by Emma Anne Harris

At Your (Data) Service: How Can We Expand Research Data Management ‘Service Portfolios’
by Emma Anne Harris
There is a lot of discussion regarding increasing Research Data Management (RDM) services from the perspective of researchers. However, understanding and supporting service providers is also crucial to embedding Open and FAIR Data approaches in institutions.
The session identified some clear trends in what is and is not being offered. Participants put that advice on Data Management Plans (DMPs), general training on RDM, and archiving support were all common services being provided. Whereas legal advice and support on sensitive data for example guidance on GDPR regulations, as well as information on collaboration and repository tools for example commasoft or the RIN data repository, were identified as services that participants wish could be provided. Time, workload, personnel, and lack of institutional buy-in were all identified as obstacles to being able to offer more RDM services.
The final discussion was about how participants felt they could expand their service portfolio. It was agreed that an underlying RDM strategy would be helpful. Several participants highlighted that better connections between departments, for example library and IT, would help, although these required careful and incremental improvements. Additional funding and staff would also be of enormous practical help. Others suggested that researchers themselves might be able to offer support and expertise in creating services that expand the RDM services offered, and that indeed bottom-up or grassroots initiatives, for example openmod, are more likely to be embedded in the long-term. The results of this workshop will be fed into the FDNext project, which will create resources to assist service providers in concretely assessing and expanding their RDM services.
Session Pad
Publication infrastructures
that support reproducibility
by Juliane Kant
Publication infrastructures that support reproducibility
by Juliane Kant

Reproducibility and transparency can be regarded (at least in experimental research) as a hallmark of research. The ability to reproduce research results using the original data and procedure (for example: code) helps to build on existing knowledge. Despite the fact that most researchers agree that reproducibility and transparency are desirable goals and part of good research practice, efforts to enhance reproducibility are still not part of everyday research.
In this session, we discussed what researchers need to publish their results reproducibly and how infrastructures can support this process. The participants mentioned that researchers need infrastructures that are easy to use, fit seamlessly in their routine workflows, are free and ideally Open Source. Examples were long-term interactive notebooks, repositories for code, electronic lab books, and platforms that link data, code and publications. These infrastructures should be based on common standards and integrate existing tools such as GitHub or GitLab, Zenodo, and R Markdown. Moreover, the continuous availability should be guaranteed. In addition, local support for researchers was deemed necessary, for instance, with regard to data management. Finally, incentives and time are essential pre-conditions for reproducible practices. Results from this session will be integrated into a project of the European initiative Knowledge Exchange on Publishing Reproducible Research Output.
Session Pad
Open Science in Elections - Engaging
Politics in Election Periods
by Stefan Skupien
Open Science in Elections – Engaging Politics in Election Periods
by Stefan Skupien

2021 is “Super election year” in Germany where several elections take place at federal and state level. Since science is increasingly part of the public discussion and since the current pandemic is used to showcase the success of Open Science practices, questions arise as to whether to engage with politics to gather more support for Open Science policies at the federal and state level.
Elections could bring more attention to the issue and force parties to include Open and quality Science in their programmes. Past elections have for instance led to the science barometer as a tool to check for science policies in general. Is this replicable in 2021?
In the session, we discussed the topic and noted the availability of national recommendations for Open Science (for example Austria) and the current support at the EU and the UNESCO for implementing Open Science practices and policies. However, we were cautious of differing motivations to support Open Science and the lack of awareness and priority for science/Open Science amongst policy-makers. At national and local levels there are a variety of networks that also focus on science policy for a more Open and fair Science ecosystem. We plan to keep ourselves informed about local initiatives (for example the innObeers: monthly Open Science & Open Innovation in Science meetup for Open Science coordinators in Berlin).
Session Pad
Further Reading:
Networks operating throughout Germany that also influence politics (and advocate for higher education policy aspects)
Conclusion: We need more barcamps on Open Science
One of our core findings from Barcamp Open Science 2021 is: Barcamps also work online, albeit differently. This has already been seen at other barcamps on Open Science, such as the barcamp at the Open Science Festival or the Barcamp@GeNeMe’2020. Advantages such as easy participation are of course offset by disadvantages such as fewer opportunities for direct exchange. And online you simply have to cut back because participation is simply more exhausting. But online and offline, barcamps are a great exchange and networking format. You can learn from each other.
We are increasingly being asked about our experience in running a barcamp, which we are happy to share. We are open to cooperation and eager to organise more barcamps around Open Science. Just check the Barcamp Open Science website for updates regularly and/or get in contact with us oscibar(at)zbw.eu or with Guido (g.scherp(at)zbw.eu) or Lambert (lambert.heller(at)@tib.eu) directly.
An overview of all sessions and the respective documentation can also be found in this Cryptpad.
Links for the Barcamp Open Science
- Website Barcamp Open Science
- How to Contact the organisers of the Barcamp Open Science
- Stay updated about Open Science and the Barcamp with the ZBW MediaTalk Newletter!
- Hashtag #oscibar
More tips for events and event reports
- Barcamp Open Science GenR report
- Open Science Conference 2021: On the Way to the New Normal
- Barcamp Open Science 2020: Learning to Make a Difference
- Open Science & Libraries 2021: 21 tips for conferences, BarCamps & Co
- ZBW-MediaTalk event calendar for further exciting events in the coming months
- Open Science Conference 2019: The Recommendations are Being Implemented Now
- Open Science Conference 2018: Going into practice!
You may also find this interesting
- Open Science and organisational culture: Openness as a core value at the ZBW
- Open Science podcasts: 7 + 3 Tips for Your Ears
- Digital Open Science Tools: How to Achieve more Openness Through an Inclusive Design
- Scoping the Open Science Infrastructure Landscape in Europe
About the authors:
Dr Sonja Bayer works as Senior Researcher at DIPF | Leibniz Institute for Research and Information in Education and is coordinating the German Network of Educational Research Data (VerbundFDB). She is interested in research on Teaching and Learning, Open Science, Research Data Management, Data Science. She can also be found on ORCID and Twitter.
Portrait: Sonja Bayer©
Dr Tim Boxhammer is a doctor of marine sciences, specialised in the field of climate change research. He has published numerous scientific articles in international peer-reviewed journals and is an advocate of Open Science. Tim was team member of the project Modern Publishing using his background to define the needs of the science community. Since 2021, he is implementing a new level of scientific journal hosting at the Hamburg State and University Library. He can also be found on ORCID and ResearchGate.
Axel Dürkop has his roots in philosophy and theatre. He works for Hamburg Open Online University (HOOU) at the Institute of Technical Education and University Didactics at the Hamburg University of Technology (TUHH) shaping Open Education and Open Science. He was team leader and developer for the project Modern Publishing at the TUHH Library in the programme Hamburg Open Science.
Florian Hagen works as subject librarian with focus on Open Access and Open Education for the University Library of the Hamburg University of Technology (TUHH). Previously, he was involved in various projects from programmes like Hamburg Open Science (HOS) and Hamburg Open Online University (HOOU) at the TUHH and responsible for training specialists in media and information services (ZBW Hamburg).
As a social scientist and academic librarian, Lambert Heller founded the Open Science Lab at TIB – Leibniz Information Centre for Science and Technology in 2013. With NFDI4culture (German), Open Research Information, Decentralized Web Applications and other grant-funded projects, the OSL helps communities in science and culture to adopt open digital tools and practices. He can also be found on LinkedIn and Twitter
Portrait: Lambert Heller©
Dr Juliane Kant is programme manager at the German Research Foundation (DFG). She is working in the area of Open Access and Digital Publishing and together with her colleagues is in charge of the funding programme Infrastructures for Scholarly Publishing. In addition, she is partner representative in the European initiative Knowledge Exchange and leads working groups in the area of Open Science and Open Access.
Portrait: Juliane Kant©
Dr Peter Kraker is founder and chairman of Open Knowledge Maps. A long-time Open Science advocate, he is known for coining the term Open Methodology and for his leading role in creating The Vienna Principles – A Vision for Scholarly Communication in the 21st Century. He can also be found on Twitter.
Portrait: Peter Kraker©, CC BY 4.0
Albert Krewinkel is a molecular biologist turned mathematician turned software engineer. He is a passionate Open Source contributor with a special interest in Open Science and publishing workflows and serves as a core developer for the universal document converter “pandoc”. After spending time in Lübeck, Hamburg, and Menlo Park, Albert now lives in Berlin with his wife and kids. He can also be found on GitHub and Twitter.
Portrait: Albert Krewinkel©
Felicitas Kruschick is graduating at the Leibniz University of Hanover on Inclusive Education in rural Ghana. She is part of the Institute of Special Education and focussing on the concept of Inclusive Education seen under the perspective of power dynamics. She is also working on a digital learning environment on Inclusive Education and is a scholarship holder of the Wikimedia Foundation Program on Open Science. She can also be found on ResearchGate and Twitter.
Portrait: Felicitas Kruschick©, CC BY-SA 4.0
Dr Thomas Lösch works as a Senior Researcher at DIPF | Leibniz Institute for Research and Information in Education. Within the “German Network for Educational Research Data” (German name: “Verbund Forschungsdaten Bildung”), he supports educational researchers in all matters related to managing and sharing research data. Part of his job also includes meta-research on Open Science in Education. He can also be found on ORCID and Twitter.
Portrait: Thomas Lösch©
Isabella Meinecke is head of the Electronic Publishing department and the library-based Hamburg University Press at the Hamburg State and University Library as well as head of the library’s Open Access unit. As the library’s Open Access representative, she has been involved in corresponding networks and activities for many years.
Dr Guido Scherp is Head of the “Open-Science-Transfer” department at the ZBW – Leibniz Information Centre for Economics and Coordinator of the Leibniz Research Alliance Open Science. He can also be found on LinkedIn and Twitter.
Portrait: ZBW©, photographer: Sven Wied
Dr Stefan Skupien is working as Scientific Coordinator for Open Science for the newly found Berlin University Alliance. One of his tasks includes the systematic survey of empirical studies on the practice of Open Science as part of an interdisciplinary research group. As a former fellow of the Open Science Fellows Program, Stefan currently finishes an Open Data Funding Observatory for African researchers.
Portrait: Stefan Skupien©, photographer Ralf Rebmann, CC BY-SA 4.0
Antonella Succurro is Scientific Officer and Postdoctoral Researcher at the West German Genome Center in Bonn. She is a member of the organisation Science for Democracy to promote the Right to Science, where she focuses on Open Science, Diversity and Inclusion, Systemic Bias in AI. She can also be found on LinkedIn, ResearchGate and Twitter.
Portrait: Antonella Succurro©
Klaus Thoden currently works for the GWDG in a collaborative project with the Max Planck Institute for the History of Science. Since 2015, he has been the Technical Manager for the Edition Open Access Publication Infrastructure. The aim of the collaboration is to implement the text conversion tools and publication platform at the GWDG in order to make these services widely available.
Michela Vignoli is Community Coordinator at Open Knowledge Maps and researcher at AIT Austrian Institute of Technology. Her focus of interest lays on knowledge management in the digital era and on how to implement and support a systemic change towards open science. He can also be found on Twitter.
Portrait: Michela Vignoli©
#bookliberationist Simon Worthington researches at the Open Science Lab at TIB – Leibniz Information Centre for Science and Technology and University Library. He is the author of “The Book Liberation Manifesto”, which outlines plans for automating publishing infrastructures to help make research accessible to all, and editor of the open research blog “Generation Research”.
Dr Philipp Zumstein is leading the publishing services and research support team at Mannheim University Library. He is the Open Access represantative of the University of Mannheim, where an Open Science Office just was established. He can also be found on GitHub, ORCID and Twitter.
Portrait: Philipp Zumstein©


Open Science, All The Way: Open Knowledge Maps

The 2019/20 Barometer for the Academic World: New Insights for Open Science?

Research Data Management: Toolbox for Successful Institutional Services
View Comments

Scientific tweets: Why Less is More and When a Tweet is Perceived as Being Scientific
Communication within the scientific community without twitter has become hard to...