
Machine Learning: How to Automate Subject Indexing
Machine-learning methods allow great progress in the automation of subject indexing. In an interview, Dr. Argie Kasprzik describes the challenges involved and how far the integration into regular operations has progressed.
we were talking to Argie Kasprzik
 Subject indexing in libraries is still costly. Machine learning methods offer the potential for facilitation at work. We spoke with Dr Argie Kasprzik about the automation of subject indexing. Since the end of 2018, she has been a research assistant at the ZBW – Leibniz Information Centre for Economics and is responsible for the management / coordination of the automation of subject indexing with machine learning methods (AutoSE).
Subject indexing in libraries is still costly. Machine learning methods offer the potential for facilitation at work. We spoke with Dr Argie Kasprzik about the automation of subject indexing. Since the end of 2018, she has been a research assistant at the ZBW – Leibniz Information Centre for Economics and is responsible for the management / coordination of the automation of subject indexing with machine learning methods (AutoSE).
She aims to create bridges between research and library operations and to ensure the transfer of research results into practice.
How do you use machine learning for automatic subject indexing in the ZBW?
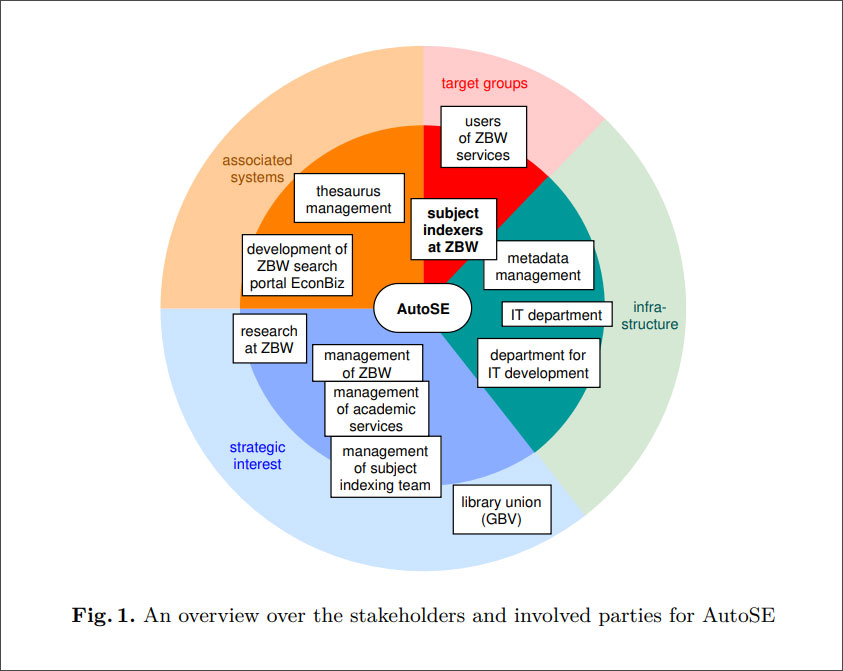
With machine learning, you always need training data first so that the machine has a pattern from which to learn. Training data in our case are metadata records for resources that were indexed intellectually using the STW Thesaurus for Economics. These are then used to train several machine learning procedures and their results are combined in a rule-based fusion approach: A STW descriptor must be proposed by at least two procedures, otherwise it will not be included; and for a resource, at least two STW descriptors must be proposed from the STW subthesauri for Business Administration or Economics.
What experience have you gained so far?
Taking the first steps with machine learning methods is easy – but getting these machine learning methods to a level that meets the requirements of our working context is a very complex task. A basic requirement is the existence of suitable training data – this applies not only to the quantity (the more, the better), but especially to its diversity: ideally, for all cases (that is, for all STW descriptors) that I want to distinguish, there should be enough metadata records in which these descriptors occur to provide the machine with enough examples from which it can learn how to achieve the desired result.
What is the status of the automation of subject indexing?
Over the course of the last few years, a machine learning-based prototypical solution has been developed in an internal ZBW research-based project. Since 2016, four copies of the EconBiz metadata base for the ZBW collection have been processed and the results have been fed back into the database. However, this solution has not yet been integrated into the other productive workflows of the library; the process had to be initiated manually.
What is the biggest challenge in automating subject indexing?
The automation of subject indexing is a balancing act between quality standards, as defined by the intellectual subject indexing to date, and technological change, which may result in new requirements and new potential in the field of retrieval.
Skip to PDF contentThe core aim of indexing of course still is to present users with the most relevant resources in response to a content-based search query, and this only makes sense if as many resources as possible are indexed, otherwise they cannot be compared – here, of course, the automation of subject indexing can help to index collections that are no longer intellectually manageable in terms of numbers. In addition, a subject indexing with our controlled vocabulary, the STW, only creates an added value compared to modern text mining algorithms if we provide the resource with structured semantic information that can be evaluated in retrieval.
The availability of external additional information, for example from the Linked Open Data Cloud, in combination with semantic technologies, opens up completely new possibilities. However, these first have to be tested for their suitability for everyday use and, step by step, cast into solutions that can be implemented in today’s library operations.
How does automated subject indexing turn from a project into a permanent task?
First of all, by officially declaring it a permanent task, prioritizing it accordingly – and providing it with the appropriate resources. We have already taken this step at the ZBW and have hired an additional software developer who will help us over the next few years to build an architecture that allows the integration of machine learning solutions into the subject indexing operation at the ZBW. This is to ensure that results from applied research are actually applied in practice.
Further Informations
- Presentation slides: “Putting Research-based Machine Learning Solutions forSubject Indexing into Practice” by Dr Argie Kasprzik.
- Conference Paper: Kasprzik, Argie: Conference Paper — Published Version: Putting Research-based Machine Learning Solutions for Subject Indexing into Practice (PDF).
- Proceedings of the Conference on Digital Curation Technologies (Qurator 2020), 20.01. – 21.01.2020 in Berlin.
- Informations about the ZBW project Automatization of Subject Indexing using methods from artificial intelligence.
Dr Argie Kasprzik coordinates and manages the automation of subject indexing with machine learning methods (AutoSE) at the ZBW – Leibniz Information Centre for Economics. Previously, she completed her doctorate in Theoretical Computer Science in Trier and a library internship (Q4) at the Library Academy of Bavaria in Munich, followed by a practical year at the Communication, Information and Media Centre (KIM) in Constance. She can also be found on Twitter.
Portrait: ZBW©, photographer: Carola Gruebner

Discrimination Through AI: To What Extent Libraries are Affected and how Staff can Find the Right Mindset

Podium Discussion: Perspectives for “Libraries 2050”

Horror Research Data Management: 4 Best Practice Examples for Successful Gamifications
View Comments

Open Science Maturity: Universities in Finland in the Leading Position
Finland has already achieved considerable milestones in fostering an open science...